Laboratorio
di Sistemi Informativi
Import/Export
ed interfacce utente
Inserire i dati con i comandi INSERT
INTO ... VALUES
è abbastanza complesso. Per fortuna, ci
sono altri metodi. È possibile inserire dati tramite un
client
dotato di interfaccia grafica più amichevole,
oppure
importare dei dati presenti in un file di testo.
Mentre il primo metodo è adatto per inserimenti di piccole
quantità di dati, il secondo ben si adatta per immettere un
numero enorme di informazioni. Queste possono venire da altri database
o
anche da programmi di tipo diverso, come fogli elettronici.
Analogamente, è possibile esportare in formato testo
i dati
presenti nelle
tabelle, in modo da renderli utilizzabili da altri
programmi.
Il comando SOURCE
Uno dei modi più semplici per copiare un database da un
server a
un altro è avere uno script che consiste di comandi SQL che
creano il database, le tabelle ed eventualmente inseriscono i dati
necessari. Ad esempio, lo script airdb.sql
esegue i comandi
necessari a ricreare il database airdb
di cui all'Esercizio 1 della lezione precedente.
Uno script è essenzialmente un file di testo composto da
vari
comandi SQL. Vediamo che lo script airdb.sql contiene una serie di
comandi che abbiamo già visto la lezione scorsa. Tuttavia,
ci
sono un paio di novità:
- DROP DATABASE IF
EXISTS
<nomedb> :
cancella il databse <nomedb> se esiste. A
differenza di DROP DATABASE
<nomedb>, la
variante con IF EXISTS
non da errore
nel caso il database <nomedb> non esiste. Per questo
è
particolarmente utile per script che ricreano un database da zero,
senza che si sappia in anticipo se un database con tale nome esiste
oppure no.
- INSERT INTO
<nometabella> VALUES (lista1), (lista2), ...
: il comando INSERT
consente di inserire
più righe nella tabella. Inserire più con un
singolo
comando comporta una maggiore velocità di esecuzione e un
risparmio sul numero di caratteri da digitare sulla tastiera.
Abbiamo spiegato il contenuto di questo script ma non abbiamo ancora
detto come eseguirlo. Ci sono fondamentalmente due modi per eseguire
uno script.
- dal prompt del monitor di SQL
eseguire il comando source
<nomefile>.
- dal prompt della shell di Linux,
eseguire il comando mysql <
<nomefile>.
Ovviamente, perchè questo comando funzioni il file
contenente lo
script deve essere nella directory corrente. Se così non
è, si può inserire, invece del semplice nome del
file
file di script, il percorso completo (assoluto o relativo) dello stesso.
Le due varianti per l'esecuzione di uno script sono simili. Tuttavia,
il comando source
restituisce un messaggio di errore (o di corretta esecuzione) alla fine
di ogni comando SQL. Se lo script è lungo, questo
può
rallentarne di molto l'esecuzione. E` preferibile, in tal caso, usare
la seconda variante.
Talvolta, il file che si vuole leggere esegue delle operazioni su
tabelle senza contenere il comando USE
necessario a selezionare il
database. Se si usa il comando SOURCE
non c'è problema, basta
dare prima il comando USE manualmente. Se si usa la forma mysql <
<nomefile>
c'è una variante che esegue uno USE
implicito prima di leggere il file: basta specificare il nome del
database con l'opzione -D
<nomedb> come
in mysql
-D <nomedb> < <nomefile>.
Esercizio 1
Eliminare il database airdb che eventualmente si trova nel vostro
server. Scaricare ed eseguire lo script airdb.sql.
Controllate che
- l'esecuzione non generi
errori
- si ottenga alla fine un
database "airdb" con una tabella aerei
dalla
seguente struttura
+------------+-------------+------+-----+---------+----------------+
|
Field |
Type
| Null | Key | Default |
Extra
|
+------------+-------------+------+-----+---------+----------------+
|
id
| smallint(6)
| | PRI |
NULL |
auto_increment |
|
produttore |
char(20)
|
|
|
|
|
|
modello |
char(20)
|
|
|
|
|
|
dataimm |
date
| YES
| |
NULL
|
|
|
numposti |
smallint(6) | YES | |
NULL
|
|
+------------+-------------+------+-----+---------+----------------+
e con due righe già inserite.
Se
l'esecuzione dello script causa
errori, controllare se si
è concesso a "studente" il
privilegio di operare sul database airdb. Consultare a proposito
l'Esercizio 3 della lezione precedente e la spiegazione del
comando grant.
ATTENZIONE!
Uno script SQL per
poter essere eseguito deve essere un file di testo. Questo vuol dire
che deve essere privo di qualsiasi tipo di formattazione. Ad esempio un
testo in HTML non può essere eseguito nè con il
comando source
nè con mysql <
<nomefile>. La
stessa cosa vale per i file di Microsoft Word (.doc), OpenOffice
(.sxw/.odw), AbiWord (.abw) e altri. In generale, se un file
è
visibile senza "stranezze" con il comando cat
dalla shell di Linux,
on con l'editor di testi usato a lezione, allora si può
usare
come script SQL.
Il comando LOAD DATA
Supponiamo ora di voler aggiungere altri elementi alla tabella aerei, e
di avere i dati in un file datiaerei.txt.
Notare che nel file sono
presenti gli stessi campi della tabella
(eccetto id):
ogni campo
è
separato da un altro da una tabulazione
(attenzione una tabulazione, non uno spazio), e ogni riga rappresenta
una nuova istanza. Il comando che utilizziamo per inserire questi dati
è
LOAD
DATA LOCAL INFILE
'datiaerei.txt' INTO TABLE aerei (produttore,modello, dataimm,numposti);
LOAD
DATA LOCAL INFILE
è il comando per caricare i dati da un file. Nel
comando
specifichiamo:
- il nome di file: datiaerei.txt
- la tabella dove inserire i
dati: aerei
- le colonne che intendiamo
inserire nella tabella (produttore,modello,
dataimm,numposti);
Notare che non inseriamo nulla per il campo id
perchè esso viene
generato automaticamente grazie alla funzione auto_increment.
Ci sono altri parametri che posso essere specificati, dopo il nome
della tabella e prima dell'elenco dei campi:
- FIELDS ENCLOSED BY
'<carattere>':
per indicare che i valori degli attributi
nel file di testo sono
racchiusi
tra una coppia di caratteri uguali;
- FIELDS TERMINATED BY
'<carattere>':
per indicare che i valori degli attributi
sono separati
tra loro dal carattere specificato, piuttosto che dalla tabulazione;
- IGNORE
<number> LINES:
per ignorare le prime <number> righe.
Ad esempio, supponiamo che il file datiaerei2.txt
contenga
queste informazioni
produttore,modello,data
immatricolazione,numposti
xyz,"columbia
shuttle",1999-6-4,5
boeing,B600,1920-2-23
È possibile importare questi dati usando il
comando:
LOAD
DATA LOCAL INFILE
'datiaerei2.txt' INTO TABLE aerei FIELDS TERMINATED BY ',' ENCLOSED BY
'"' IGNORE 1 LINES (produttore,modello, dataimm,numposti);
Notare che la parola FIELDS
non va
ripetuto in FIELDS ENCLOSED BY
poichè
è già presente in FIELDS
TERMINATED BY.
Il risultato finale dovrebbe essere qualcosa del tipo:
+----+------------+------------+------------+----------+
| id | produttore | modello | dataimm | numposti |
+----+------------+------------+------------+----------+
| 1 | boeing | 747 | 2000-10-10 | 350 |
| 2 | MDD | Super80 | NULL | NULL |
| 3 | boeing | 747m | 2000-01-01 | 200 |
| 4 | boeing | 747m | 2000-01-01 | 200 |
| 5 | airbus | b200 | NULL | NULL |
| 6 | xyz | concorde | 1980-07-03 | 110 |
| 7 | xyz | columbia s | 1999-06-04 | 5 |
| 8 | boeing | B600 | 1920-02-23 | NULL |
+----+------------+------------+------------+----------+
a parte i valori per il campo id.
Esempio: Importazione dati da
OpenOffice
Il metodo visto sopra può anche essere utilizzato per
importare
dati da altri programma, ad esempio da fogli elettronici o da altri
database. Supponiamo di avere una tabella
OpenOffice
contenente i seguenti dati:
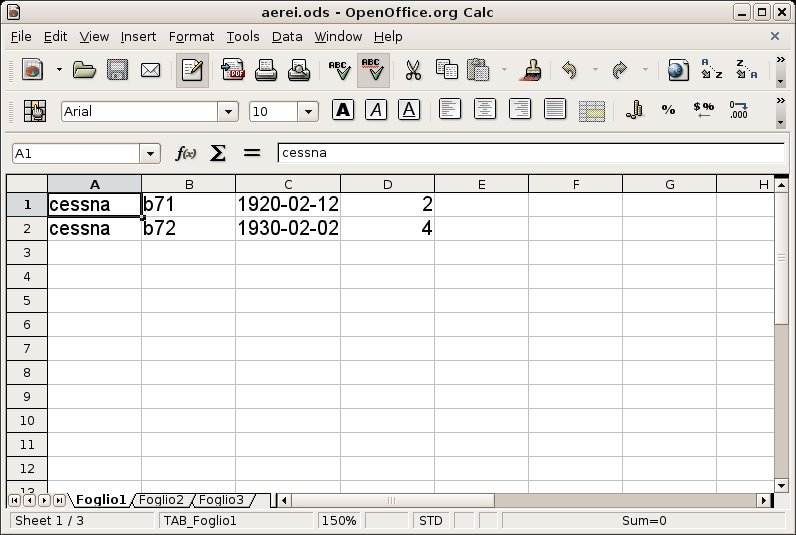
Sono possibili due strade per importare questi dati in MySQL
- È possibile
copiare i dati e incollarli in un file di
testo, ad
esempio dentro una finestra di gedit. Una volta salvato il file di
testo, supponiamo col nome aerei.txt,
si possono importare i dati in
MySQL con
LOAD DATA LOCAL INFILE
'aerei.txt' INTO TABLE aerei (produttore,modello,dataimm,numposti);
- È possibile
salvare il foglio OpenOffice in formato "Testo
CSV". Il programma chiede il carattere da usare come delimitatore di
campo e quello da utilizzare per racchiudere i campi di testo (di
default rispettivamente la
virgola e le virgolette):
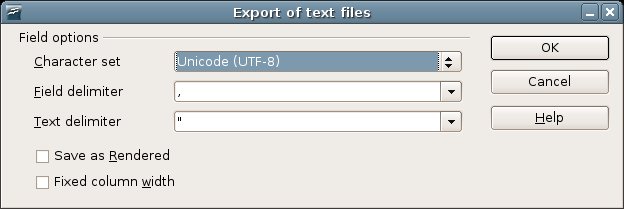
Se non si modificano i caratteri delimitatori e si utilizza il
nome di file aerei.csv, si possono importare i dati in MySQL con il
comando
LOAD
DATA LOCAL INFILE
'aerei.csv' INTO TABLE aerei FIELDS TERMINATED BY
',' ENCLOSED BY
'"' (produttore,modello,dataimm,numposti);
ATTENZIONE!
Per essere sicuri che le date siano memorizzate
nel file
.CSV con il formato gradito a MySQL, accertarsi che esse vengano
visualizzate sul foglio di calcolo in maniera appropriata, e
selezionare
l'opzione "Save as Rendered".
Esercizio 2
Nel nostro database airdb si vuole creare una tabella che
contiene
informazioni sui posti relativi ad ogni aereo. La tabella
contiene
i seguenti campi:
- idaereo: l'aereo a cui il
posto si riferisce
- numposto: il numero del posto
- classe: può
essere business class, first class o turistica
- collocazione: finestrino,
corridoio, interno
Visto che la quantità di righe da generare è
notevole
(solo per l'aereo 1 si tratta di inserire 350 righe) si vuole
automatizzare la fase di inserimento. Si vuol far generare i dati a un
programma (scritto in C o in altro linguaggio di programmazione) e
importarli in MySQL.
Ad esempio, il seguente programma in C
#include
<stdio.h>
#define
NUMPOSTI 350
#define
NUMAEREO 1
#define
POSTI_FIRST 40
#define
POSTI_BUSINESS 100
main()
{
int i;
for (i=1; i<NUMPOSTI;
i++) {
if(i<=POSTI_FIRST)
printf("%d %d %s\n",NUMAEREO,i,"first");
else
if(i<=POSTI_BUSINESS)
printf("%d %d %s\n",NUMAEREO,i,"business");
else
printf("%d %d %s\n",NUMAEREO,i,"turistica");
}
}
genera i dati in datiposti.txt
di cui
facciamo vedere le prime linee:
1
1 first
1
2 first
...
1
121 turistica
1
122 turistica
1
123 turistica
...
Creare una nuova tabella "posti" con i campi opportuni e inserire i
valori generati dal programma di sopra. Qual è una possibile
chiave primaria per la tabella posti?
Per controllare se i dati sono inseriti si può usare il
seguente
comando:
SELECT
* FROM postio LIMIT <n1>,<n2>
che visualizza solo i primi n2 elementi della tabella posti a
partire
dall'elemento n1-esimo.
Esportazione dei dati con
mysqldump
Oltre che importare i dati in MySQL, è necessario talvolta
esportarli ad altri programmi. Uno dei modi più semplici
è utilizzare il comando mysqldump.
Ci
sono vari modi per utilizzarlo. Il più conveniente
è con
la sintassi:
mysqldump
<nomedb>
che lista l'insieme dei comandi necessari per ricostruire esattamente
il database <nomedb>
allo stato attuale. Possiamo anche salvare
il
contenuto del file, invece di guardarlo sullo schermo, con
mysqldump
<nomedb> >
<nomefile>
Il file che è ottenuto può essere letto con il
comando SOURCE
da dentro MySQL Client.
Bisogna prima ricordarsi di selezionare il database in cui si vogliono
inserire i dati con il comando USE,
visto che mysqldump
non
lo genera. Alternativamente, dalla shell di Linux possiamo dare il
comando mysql -D
<nomedb>
< <nomefile>.
Con la sintassi
mysqldump <nomedb> --databases
<db1>...<dbn>
si può specificare più di un database. Inoltre mysqldump
genera anche i
comandi per creare le basi di dati ed i comandi USE.
Il file generato,
pertanto, può essere letto con il monitor di MySQL, sempre
con
il comando SOURCE,
o con mysql
< <nomefile>
(l'opzione -D non è più necessaria
perchè i
comandi USE necessari
sono inseriti dentro il file).
Gli script creati con mysqldump
possono essere eseguiti, come visto,
con il comando source.
Anzi, esportare i dati con mysqldump
e
rileggerli da un altra macchina con source
è il modo
migliore
per trasferire dati da un sistema ad un altro, in quanto funziona
indipendentemente dal tipo di sistema operativo o processore utilizzato
nei due sistemi.
Esportazione diretta dei file
del database
Un altra possibilità per esportare i propri dati
è
copiare manualmente i file che contengono i database presenti nel
server. Il server MySQL conserva tutti i propri dati nella directory
/var/lib/mysql. Qui sono presenti varie directory, una per
ogni
database creato nel sistema. Dentro ogni directory, e per ogni tabella,
vi sono tre file: <tabella>.frm,
<tabella>.MYD
e <tabella>.MYI.
Se si copiano questi file e si spostano in un altro server,
quest'ultimo vedrà il nuovo database esattamente nello stato
in
cui era nel server originale. Però, questo metodo ha alcuni
svantaggi:
- nella maggior parte dei
casi, solo il super-utente ha il diritto
di accedere alla directory /var/lib/mysql/<database>.
- prima di copiare i dati dal
server origine è necessario
che il processo server di MySQL venga disattivato, altrimenti si
rischia di copiare dei file corrotti. Analogamente, prima di copia i
file nel server destinazione, è bene che anche qui il
processo
server venga disattivato.
Normalmente, spostando file binari da un sistema ad un altro,
c'è anche il rischio che, cambiando processore o sistema
operativo, il file non sia più leggibile. Questo non succede
di
solito con MySQL perchè il formato di memorizzazione dei
database è standardizzato ed è esattamente uguale
per
tutte le macchine su cui esso gira.
Interfacce utente di MySQL
Fino ad ora abbiamo sempre usato MySQL utilizzando come client il
programma "monitor". In questo
modo abbiamo potuto fare pratica con i comandi SQL senza essere
"tentati" dall'interfaccia grafica. Tuttavia, queste ultime esistono, e
nell'uso quotidiano è possibile trovarle più
comode del
monitor di SQL.
In realtà, ne esistono varie di queste interfacce grafiche,
che
è possibile scaricare come sempre dal sito web di MySQL.
Quelle
più recenti sono
- MySQL
Administrator. E` sviluppato per
chi deve amministrare il
server MySQL o uno dei suoi database. Consente facilmente di
modificare, creare o distruggere database, tabelle, indici e utenti.
(Cosa sono indici e utenti lo vedremo tra un po') Consente anche
l'accesso a tutta una serie di parametri interni di MySQL che
consentono di ottimizzarne le prestazioni.
- MySQL
Query Browser consente invece di
operare facilmente con il
contenuto di un database, eseguendo interrogazioni e modificando i dati.
Ovviamente, come nel caso del monitor di MySQL, è possibile
collegarsi a un server remoto: basta specificare il nome del computer a
cui collegarsi, nome utente e password (se necessaria) da usare per il
collegamento.