Laboratorio
di Sistemi Informativi
SQL:
un breve ripasso
Questa lezione è dedicata a un breve ripasso dei comandi di
interrogazione e manipolazione dati di SQL.
Il comando SELECT
Abbiamo visto nelle lezioni precedenti
come usare il comando SELECT
per esaminare il contenuto di una tabella. Il comando
SELECT è probabilmente il comando più complesso
di SQL e
consente di effettuare query di vario tipo.
La sintassi standard di SELECT è la seguente:
SELECT
<lista di colonne>
FROM <lista di tabelle> WHERE <condizione>
Questa operazione esegue il θ-JOIN delle tabelle indicate
FROM
secondo
la
condizione specificata, e visualizza le colonne indicate. Se si mette
l'asterisco * al posto della lista colonna, vuol dire che si intende
visualizzare tutti i campi disponili.
Ad esempio, consideriamo il database creato dallo script esempioselect.sql.
Possiamo vedere quali
sono i valori inseriti nella tabella t1 col comando:
SELECT
* FROM t1;
o possamo decidere di visualizzare soltanto i nomi presenti nella
tabella t1 con
SELECT
nome FROM t1;
ottenendo
+-------+
|
nome |
+-------+
|
pippo |
|
pluto |
|
caio |
|
pluto |
+-------+
Molto più interessante è un esempio che coinvolge
più di una tabella. Ad esempio, per sapere che stipendio
corrisponde a ogni persona della tabella t1, possiamo dare il comando
SELECT
* FROM t1, t2 WHERE id=id2;
+------+-------+------+-----------+
|
id | nome |
id2 | stipendio |
+------+-------+------+-----------+
|
1 | pippo
| 1
| 1000 |
|
3 |
caio | 3
| 3000 |
|
2 | pluto
| 2
| 1900 |
+------+-------+------+-----------+
o, meglio ancora,
SELECT
nome,stipendio
FROM t1, t2 WHERE
id=id2;
+-------+-----------+
|
nome | stipendio |
+-------+-----------+
|
pippo
| 1000 |
|
caio
| 3000 |
|
pluto
| 1900 |
+-------+-----------+
Possiamo dare anche condizioni più complesse, ad esempio
richiedere gli stessi dati di prima ma solo per le persone con
stipendio
superiore a 2000:
SELECT
nome,stipendio FROM t1, t2
WHERE id=id2 and
stipendio
> 2000;
+------+-----------+
|
nome | stipendio |
+------+-----------+
|
caio
| 3000 |
+------+-----------+
Possiamo anche usare delle funzioni
intrinseche oppure operatori
di MySQL all'interno
del comando SELECT. Le funzioni intrinseche sono
simili
alle funzioni dei linguaggi di programmazione tradizionale, come il C o
il Java: prendono un certo numero di argomenti come parametri e
restituiscono un risultato. Ad esempio la funzione intrinseca concat()
prende un numero a
piacere di stringhe come argomenti e restituisce la stringa ottenuta
dalla loro concatenazione (è quindi simile all'operatore +
per
le stringhe di Java, che però non esiste in MySQL, dove + si
può usare solo con numeri).
Ad esempio
SELECT
concat(nome,' guadagna
',stipendio) FROM
t1, t2 WHERE id=id2
usa la funzione intrinseca concat
mentre
SELECT nome,stipendio FROM t1, t2 WHERE id=id2 and stipendio *
1.2 > 2000
usa l'operatore *.
Vedremo in una lezione successiva alcune delle funzioni che
MySQL mette a disposizione.
È anche possibile fare delle query con
più di una
tabella di
base. Ad esempio, la tabella t3 contiene gli indirizzi delle persone
nella tabella t1. Se vogliamo sapere nome, stipendio e indirizzo per
ogni persona, il comando da dare è:
SELECT
nome,stipendio,indirizzo FROM t1, t2, t3 WHERE id=t2.id2
and id=t3.id2;
Notare l'uso della forma t2.id2
e t3.id2
per identificare
i
campi id2 delle tabelle t2 e t3. Poichè i campi hanno le
stesso
nome, è necessario indicare anche a quale tabella ci si
riferisce.
In realtà il comando SELECT ha varie altre
possibilità
che non abbiamo visto. Esaminiamone qualcuna:
- la clausola AS nella lista
dei campi... ad esempio
SELECT concat(nome,' guadagna
',stipendio) as risultato
FROM t1, t2 WHERE
id=id2;
+---------------------+
|
risultato
|
+---------------------+
|
pippo guadagna 1000 |
|
caio guadagna 3000 |
|
pluto guadagna 1900 |
+---------------------+
È più leggibile delle versione senza as.
- la
clausola AS nella
lista delle tabelle... ad esempio
SELECT
nome,stipendio,indirizzo FROM t1 as
nomi, t2 as
stipendi, t3 as
indirizzi WHERE
id=stipendi.id2 and id=indirizzi.id2;
Viene
usata per dare degli alias comprensibili ai
nomi delle tabelle t1, t2 e t3. In realtà spesso
accade il
contrario: le tabelle hanno nomi descrittivi ma lunghi, e si usa il
comando as per poter utilizzare degli alias più corti, e
quindi
scrivere meno, all'interno di una query.
- la clausola ORDER BY... ad
esempio
SELECT
nome,stipendio FROM
t1, t2 WHERE id=id2 ORDER BY nome;
+-------+-----------+
|
nome | stipendio |
+-------+-----------+
|
caio
| 3000 |
|
pippo
| 1000 |
|
pluto
| 1900 |
+-------+-----------+
oppure in ordine
discendente
SELECT nome,stipendio
FROM t1, t2 WHERE id=id2 ORDER BY nome DESC;
+-------+-----------+
|
nome | stipendio |
+-------+-----------+
|
pluto
| 1900 |
|
pippo
| 1000 |
|
caio
| 3000 |
+-------+-----------+
- la
clausola DISTINCT
SELECT
DISTINCT
nome FROM t1;
+-------+
|
nome |
+-------+
|
pippo |
|
pluto |
|
caio |
+-------+
Join esterni
Consideriamo ancora il database di esempio creato dallo script esempioselect.sql.
Consta di varie
tabelle, in particolare ci interessano la t1 e la t2:
Tabella
t1
+------+-------+
|
id | nome |
+------+-------+
|
1 | pippo |
|
2 | pluto |
|
3 |
caio |
|
4 | pluto |
+------+-------+
Tabella
t2
+------+-----------+
|
id2 | stipendio |
+------+-----------+
|
1
| 1000 |
|
3
| 3000 |
|
2
| 1900 |
|
7
|
10 |
+------+-----------+
Supponiamo di voler sapere, per ogni persona, il relativo stipendio.
Una possibilità è il comando:
SELECT
id, nome, stipendio FROM
t1,t2 where id=id2;
+------+-------+-----------+
|
id | nome |
stipendio |
+------+-------+-----------+
|
1 | pippo
| 1000 |
|
3 |
caio | 3000
|
|
2 | pluto
| 1900 |
+------+-------+-----------+
La query non restituisce nulla riguardo allo stipendio della persona
con id 4 (che è un omonimo della persona di id 2). Questo
perchè nella tabella t2 non c'è alcuna riga con
id pari a
4. Se volessimo avere comunque informazioni su tutte le persone, anche
quelle senza stipendio, dovremmo utilizzare i join esterni:
SELECT
id, nome, stipendio FROM t1 LEFT
JOIN t2 ON
id=id2;
+------+-------+-----------+
|
id | nome |
stipendio |
+------+-------+-----------+
|
1 | pippo
| 1000 |
|
2 | pluto
| 1900 |
|
3 |
caio | 3000
|
|
4 | pluto
| NULL |
+------+-------+-----------+
Il campio stipendio relativo all'id4 è riempito con NULL.
Analogamente abbiamo anche il RIGHT JOIN:
SELECT
id, nome, stipendio FROM t1 RIGHT
JOIN t2 ON
id=id2;
+------+-------+-----------+
|
id | nome |
stipendio |
+------+-------+-----------+
|
1 | pippo
| 1000 |
|
3 |
caio | 3000
|
|
2 | pluto
| 1900 |
|
NULL | NULL
|
10 |
+------+-------+-----------+
MySQL non dispone del FULL OUTER JOIN, ovvero della
possibilità
di combinare il LEFT e il RIGHT join, in modo da considerare sia le
righe della prima tabella senza valori corrispondenti della seconda,
sia
il viceversa. Se esistesse, il FULL OUTER JOIN si comporterebbe in
questo modo:
SELECT
id, nome, stipendio FROM t1 FULL
OUTER JOIN t2
ON id=id2;
+------+-------+-----------+
|
id | nome |
stipendio |
+------+-------+-----------+
|
1 | pippo
| 1000 |
|
3 |
caio | 3000
|
|
2 | pluto
| 1900 |
|
NULL | NULL
|
10 |
| 4 | pluto | NULL
|
+------+-------+-----------+
Attenzione!
Dopo la clausola ON
vanno indicate soltanto
le
condizioni relative al join. Eventuali altre
condizioni vanno di solito indicate, come prima, nella clausola WHERE.
Ad esempio:
SELECT id, nome, stipendio FROM t1 LEFT JOIN t2 ON id=id2 WHERE
stipendio>1000;
+------+-------+-----------+
| id | nome | stipendio |
+------+-------+-----------+
| 3 | caio
| 3000
|
| 2 | pluto
| 1900 |
+------+-------+-----------+
2 rows in set (0.00 sec)
mentre
SELECT
id, nome, stipendio FROM
t1 LEFT JOIN t2 ON id=id2 and stipendio>1600;
+------+-------+-----------+
|
id | nome |
stipendio |
+------+-------+-----------+
|
1 | pippo
| NULL |
|
2 | pluto
| 1900 |
|
3 |
caio | 3000
|
|
4 | pluto
| NULL |
+------+-------+-----------+
4
rows in set (0.00 sec)
Nella maggioranza dei casi, quello che vogliamo è il primo
risultato e non il secondo.
Union
Un'altrà possibilità del comando SELECT
è quella
di eseguire due selezioni distinte e di fondere i risultati come se
fossero stati ottenuti da un comando solo. Tutto ciò si
realizza
con la clausola UNION. Ad esempio:
select
* from t1 UNION
select * from t2;
visualizza il contenuto della prima e della seconda tabella una dopo
l'altro.
Notare che elementi duplicati vengono eliminati.. Questo ci
consente di simulare il full outer join:
SELECT
id, nome, stipendio FROM
t1 LEFT JOIN t2 on id=id2
UNION
SELECT id, nome,
stipendio FROM t1 RIGHT JOIN t2 on id=id2;
È possibile anche
effettuare una union che non elimini i
duplicati, con la clausola UNION
ALL:
SELECT id, nome, stipendio FROM t1 LEFT JOIN t2 on id=id2
UNION ALL SELECT id, nome,
stipendio FROM t1 RIGHT JOIN t2 on id=id2;
+------+-------+-----------+
|
id | nome |
stipendio |
+------+-------+-----------+
|
1 | pippo
| 1000 |
|
3 |
caio | 3000
|
|
2 | pluto
| 1900 |
|
NULL | NULL
|
10 |
| 4 | pluto | NULL
|
|
1 | pippo
| 1000 |
|
2 | pluto
| 1900 |
|
3 |
caio | 3000
|
|
4 | pluto
| NULL |
+------+-------+-----------+
La clausola GROUP BY
Altra caratteristica del comando SELECT,
è la
capacità di raggruppare le informazioni in base al valore
assunto
da uno o più campi e di fornire informazioni statistiche su
questi gruppi. Utilizzeremo a questo scopo la tabella t4:
+----------+--------+-----------+
|
nome |
valore | categoria |
+----------+--------+-----------+
|
giuseppe |
100 |
a
|
|
marco
| 200 |
b
|
|
luca
| NULL |
b
|
|
luca
| 100 |
b
|
|
NULL
| NULL |
b
|
|
carlo
| 1000 |
a
|
+----------+--------+-----------+
Supponiamo di dare il comando
SELECT
* FROM t4 GROUP BY
categoria;
+----------+--------+-----------+
|
nome |
valore | categoria |
+----------+--------+-----------+
|
giuseppe |
100 |
a
|
|
marco
| 200 |
b
|
+----------+--------+-----------+
Con
l'aggiunta di GROUP BY,
per ogni valore di
categoria viene visualizzata una e una sola riga corrispondente (la
prima). Questa cosa ha di per se poca utilità, ma diventa
molto
utile quando abbinata alle funzioni aggregate, che consentono di
effettuare varie operazioni statistiche.
Ad esempio, se si vuole conoscere il numero di persone appartenente ad
ogni categoria, possiamo dare il comando:
SELECT
categoria, COUNT(*)
FROM t4 GROUP BY
categoria;
+-----------+----------+
|
categoria | COUNT(*) |
+-----------+----------+
|
a
|
2 |
|
b
|
4 |
+-----------+----------+
La clausola GROUP BY
divide tutte le informazioni in gruppi, ogni gruppo caratterizzato dal
fatto di avere la stessa categoria mentre COUNT(*)
conta il numero di
elementi in ogni gruppo.
Notare che nel conteggio viene anche inserita la riga
(NULL,NULL,'b'). Se si vuole essere più precisi su
cosa
contare, possiamo indicare tra parentesi a COUNT un nome di un campo. A
questo punto, le linee in cui il campo indicato contiene il valore null
verranno escluse dal conteggio. Ad esempio:
SELECT categoria, COUNT(nome)
FROM t4 GROUP BY categoria;
+-----------+-------------+
|
categoria | COUNT(nome) |
+-----------+-------------+
|
a
|
2 |
|
b
|
3 |
+-----------+-------------+
Infine è possibile indicare che occorre contare i valori
senza
ripetizioni. Ad esempio
SELECT
categoria, COUNT(DISTINCT nome)
FROM
t4 GROUP BY categoria;
+-----------+---------------+
|
categoria | COUNT(valore) |
+-----------+---------------+
|
a
|
2 |
|
b
|
2 |
+-----------+---------------+
Esitono altre funzioni
aggregate. Ad esempio la somma (SUM) e la
media (AVG):
SELECT
categoria, SUM(valore)
FROM t4 GROUP
BY categoria;
+-----------+-------------+
|
categoria | SUM(valore) |
+-----------+-------------+
|
a
|
1100 |
|
b
|
300 |
+-----------+-------------+
SELECT
categoria, AVG(valore)
FROM t4 GROUP
BY categoria;
+-----------+-------------+
|
categoria | AVG(valore) |
+-----------+-------------+
|
a
|
550.0000 |
|
b
|
150.0000 |
+-----------+-------------+
Altre funzioni aggregate sono il massimo MAX(), il minimo MIN(), e la
deviazione standard STD().
La clausola HAVING
Le condizioni che si possono specificare con la clausola WHERE sono
anche molto complesse, ma non possono riferirsi ai risultati delle
funzioni aggregate. Ovvero, non è possibile sapere l'insieme
delle categorie, nella tabella t4, che hanno un valore medio superiore
a
200. Un comando del tipo:
select
categoria,avg(valore) from
t4 where avg(valore)>400 group by categoria;
genera errore. Tuttavia, condizioni di questo tipo possono essere
espresse con la clausola HAVING.
select
categoria, avg(valore)
from t4 group by categoria HAVING
AVG(valore)>400;
+-----------+-------------+
|
categoria | avg(valore) |
+-----------+-------------+
|
a
|
550.0000 |
+-----------+-------------+
Notare che con HAVING
si
possono specificare solo condizioni che coinvolgono i campi presenti
nella clausola GROUP BY
o
il risultato di funzioni aggregate. Condizioni di altro tipo DEVONO
essere specificate nella
clausola WHERE.
Ad
esempio:
SELECT
categoria, SUM(VALORE)
FROM t4 WHERE
valore>100
GROUP
BY categoria;
+-----------+-------------+
|
categoria | SUM(VALORE) |
+-----------+-------------+
|
a
|
1100 |
|
b
|
300 |
+-----------+-------------+
mentre
SELECT
categoria, SUM(VALORE)
FROM t4 GROUP BY categoria HAVING
valore>100;
genera un errore di sintassi.
Nota!
Nell'esecuzione di un
comando SELECT,
il
linguaggio SQL prima considera la clasuole FROM
e WHERE,
calcola il risultato, e
solo successivamente considera le eventuali clausole GROUP BY
e HAVING.
Per questo motivo,
nella clausola WHERE
vanno le condizioni da applicare per filtrare l'insieme di prima di
effettuare il raggruppamento, e nella clausola HAVING
quelle per filtrare i
risultati dopo aver raggruppato.
Subqueries
Infine, un comando SELECT può anche apparire come
sotto-interrogazione di un altro comando SELECT principale. In
particolare, una SELECT può apparire
- nella clasuola FROM di
un'altra interrogazione, come in
SELECT AVG(s) FROM (SELECT
SUM(valore) AS s FROM t4 GROUP BY categoria)
AS t4;
che visualizza la media della somma degli stipendi degli impiegati di
categoria A e di categoria B;
- all'interno della condizione
WHERE, come in
SELECT * FROM t1 WHERE
id NOT IN (SELECT
id2 FROM t2);
che visualizza gli impiegati in t1 che non hanno uno stipendio
specificato in t2.
Non approfondiamo di più il discorso, perché le
possibilità offerte dallaùe subqeries sono tantissime e
non abbiamo tempo per analizzarle (anche tenendo conto che le avete
viste nel corso di Basi di Dati). Puntualizziamo solo due cose:
- molte interrogazioni con subqueries possono essere trasformate in
interrogazioni normali usando opportunamente i join esterni o delle
tabelle temporanee. Ad esempio, la seconda interrogazione di cui sopra,
si può riscrivere come
SELECT id, nome FROM t1 LEFT JOIN t2 ON id=id2 WHERE id2 IS
NULL
- il supporto per le subqueries è stato inserito in MySQL
solo con la versione 4.1.
Il database airdb
Prima di passare ad effettuare degli esercizi sul comando SELECT,
completiamo la
costruzione del database airdb,
aggiungendo nuove tabelle necessarie per la gestione dei voli e delle
prenotazioni. Il diagramma ER complessivo (schema concettuale)
per il nostro
database è il seguente:
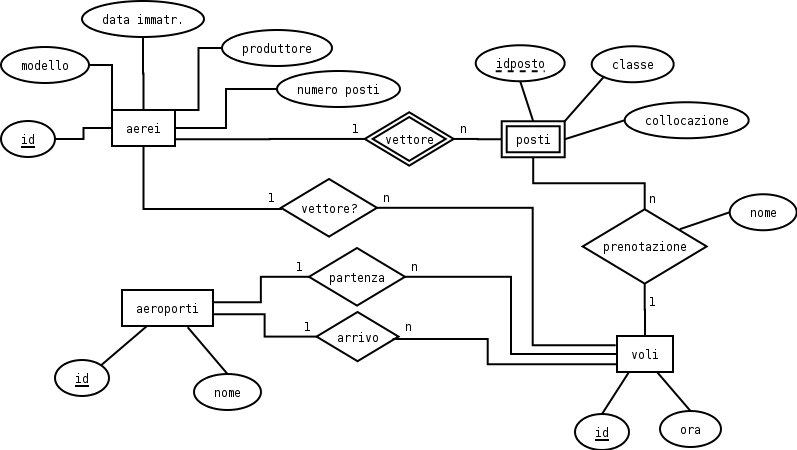
che corrisponde alla seguente struttura relazionale (schema logico)
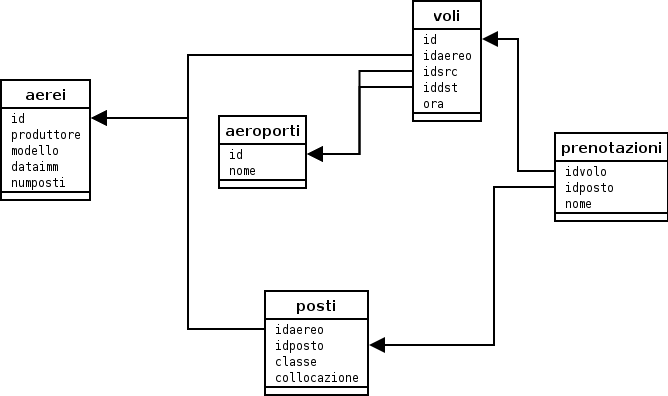
Il database può essere creato eseguendo lo script airdb2.sql
con il comando SOURCE.
Questo crea le seguenti tabelle (schema
fisico), che corrispondono
allo schema logico di cui sopra:
mysql>
describe aerei;
+------------+-------------+------+-----+---------+----------------+
|
Field |
Type
| Null | Key | Default |
Extra
|
+------------+-------------+------+-----+---------+----------------+
|
id
| smallint(6)
| | PRI |
NULL |
auto_increment |
|
produttore |
char(20)
|
|
|
|
|
|
modello |
char(20)
|
|
|
|
|
|
dataimm |
date
| YES
| |
NULL
|
|
|
numposti |
smallint(6) | YES | |
NULL
|
|
+------------+-------------+------+-----+---------+----------------+
mysql>
describe posti;
+--------------+------------------------------------+------+-----+---------+-------+
|
Field
|
Type
| Null | Key | Default | Extra |
+--------------+------------------------------------+------+-----+---------+-------+
|
idaereo |
smallint(6)
| | PRI |
0
| |
|
idposto |
smallint(6)
| | PRI |
0
| |
|
classe |
enum('business','first','economy') | YES
|
| NULL
| |
|
collocazione |
enum('finestrino','corridoio')
| YES
| |
NULL
| |
+--------------+------------------------------------+------+-----+---------+-------+
mysql>
describe aeroporti;
+-------+--------------+------+-----+---------+-------+
|
Field |
Type
| Null | Key |
Default | Extra |
+-------+--------------+------+-----+---------+-------+
|
id |
char(3)
| |
PRI
|
| |
|
nome | varchar(100) |
YES | |
NULL
| |
+-------+--------------+------+-----+---------+-------+
mysql>
describe voli;
+---------+-------------+------+-----+---------+----------------+
|
Field |
Type
| Null | Key | Default |
Extra
|
+---------+-------------+------+-----+---------+----------------+
|
id | smallint(6)
| | PRI |
NULL |
auto_increment |
|
idaereo | tinyint(4)
|
| |
0
|
|
|
idsrc |
char(3)
|
|
|
|
|
|
iddst |
char(3)
|
|
|
|
|
|
ora |
datetime | YES
| |
NULL
|
|
+---------+-------------+------+-----+---------+----------------+
mysql>
describe prenotazioni;
+---------+-------------+------+-----+---------+-------+
|
Field |
Type
| Null | Key | Default |
Extra |
+---------+-------------+------+-----+---------+-------+
|
idvolo | smallint(6)
| | PRI |
0
| |
|
idposto | smallint(6)
| | PRI |
0
| |
|
nome |
varchar(40) | YES | |
NULL
| |
+---------+-------------+------+-----+---------+-------+
ATTENZIONE!
Una
particolarità di questo schema logico è che non
è
possibile fare un join direttamente tra le tabelle prenotazioni e
posti. Infatti, la chiave primaria della tabella posti è la
coppia (idaereo, idposto), mentre la tabella prenotazioni ha come
chiave esterna soltanto idposto. Se si vuole eseguire un join tra
prenotazioni e posti bisogna introdurre anche la tabella voli, dalla
quale è possibile risalire all'id dell'aereo su cui viene
eseguito il volo.
In pratica, un comando SELECT del tipo
SELECT......
FROM prenotazioni,
posti WHERE prenotazioni.idposto=posti.idposto .....
non va bene, e va sostituito con
SELECT......
FROM prenotazioni,
posti,voli WHERE prenotazioni.idposto=posti.idposto and idvolo=id and
voli.idaereo=posti.idaereo...
Esercizio 1
Sul database airdb,
provare ad eseguire le seguenti query:
- determinare l'elenco dei
voli che partono da Pescara;
- determinare l'elenco delle
persone che hanno una prenotazione in
prima classe;
- determinare l'elenco dei
voli che hanno prenotazioni in attivo;
- determinare le persone che
hanno prenotazioni su due voli diversi
(SUGGERIMENTO: effettuare il join della tabella prenotazioni con se
stessa).
Esercizio 2
Sul database airdb,
provare ad eseguire le seguenti query,che richiedono l'uso delle
funzioni di aggregazione di SQL:
- visualizzare, per ogni volo,
il numero di posti in business class
che sono stati prenotati;
- visualizzare il numero
totale di prenotazioni per ogni volo,
includendo i voli senza prenotazioni;
- visualizzare le persone che
hanno più di una prenotazione
in corso, e il relativo numero di prenotazioni.
I comandi di manipolazione dati
Vediamo ora brevemente alcuni comandi per la manipolazione
dei
dati. Si usano come riferimento per gli esempi le tabelle create dallo
script esempioselect.sql.
- INSERT INTO
<nometabella>(<nomecampi>) VALUES
(<lista valori>):
per l'inserimento di una riga in tabella, che abbiamo già
visto
ampiamente.
- UPDATE
<nometabella> SET
<nomecolonna>=<dato> WHERE
<condizione>:
aggiorna il valore del campo <nomecolonna> con il valore
<dato>, per tutte le righe che soddisfano la condizione.
Il dato
può anche contenere espressioni aritmetiche.
Così, per
aumentare le colonne valore del 20% nella tabella t4 per tutti i membri
della categoria 'b', si può dare il comando:
UPDATE
t4 SET
valore=1.2*valore WHERE categoria='b';
- DELETE FROM
<nometabella> WHERE <condizione>:
cancella tutte le
righe in <nometabella> che soddisfano la condizione. Ad
esempio:
DELETE
FROM t4 WHERE
categoria='a';
Se non si specifica
alcuna condizione, vengono cancellate
tutte le righe della tabella.
Attenzione che eliminare una tabella è diverso da eliminare
tutte le righe di una tabella. Se una tabella viene elininata con DROP TABLE
questa sparisce dal
database e se si vuole riutilizzare bisogna crearla di nuovo. Il
comando DELETE FROM
invece svuota il contenuto della tabella, ma questa rimane nel database
ed è possibile in qualunque momento inserire nuovi elementi
con
il comando INSERT.
Infine, c'è un comando che combina le caratteristiche in di
INSERT e SELECT. Si tratta di
- INSERT
INTO
<nometabell>(<nomecampi>) SELECT
<comando select>: esegue il comando SELECT e mette il
risultato dentro
<nometabella>.
Ad esempio:
CREATE
TABLE t5 (nome char(20));
INSERT
INTO t5 SELECT nome FROM
t4;
crea e riempie una tabella con i nomi delle persone in t4:
+----------+
|
nome |
+----------+
|
giuseppe |
|
marco |
|
luca |
|
luca |
|
NULL |
|
carlo |
+----------+
Esercizio 3
Abbiamo visto che in vecchie versioni di MySQL il comando seguente non
è ammesso:
SELECT AVG(s) FROM (SELECT
SUM(valore) AS s FROM t4 GROUP BY categoria)
AS t4;
Risolvere comunque questa query adoperando una tabella temporanea per
immagazzinare il risultato di SELECT
SUM(valore) AS s FROM t4 GROUP BY categoria.
Esercizio 4
Come probabilmente avrete già notato, le prenotazioni inserite
nel database airdb hanno dei nomi inventati, composti
da due parole scelte a caso dal dizionario inglese. Nel file italian.txt
trovate un elenco di parole in
italiano. Modificare la tabella prenotazioni, sostituendo ai nomi in
inglese dei nomi costruiti allo stesso modo, ma in italiano.
A questo scopo, possono risultare utili le seguenti funzioni
intrinseche:
- rand():
che
restituisce un numero casuale tra 0 e 1
- concat(<stringa1>,
....,
<stringan>):
che concatena le stringhe in una stringa sola
- ceiling(<x>):
restituisce la parte intera superiore di x (i.e. ceiling(1.2)=2).
Un suggerimento? Cominciate con i seguenti sotto-esercizi:
- caricare in MySQL il
dizionario italiano, mettendo i dati in una
apposita tabella;
- aggiungere una nuova colonna
alla tabella prenotazioni, e
riempirla con valori casuali interi tra 1 e il numero di righe di italian.txt;
- fare una join tra la tabella
prenotazioni e il dizionario usando
il valore casuale generato come indice nella tabella dizionario.
Se volete proprio strafare, potete provare a modificare i nomi in modo
da avere l'iniziale del nome e del cognome maiuscolo. A tal scopo, sono
utili le seguenti funzioni intrinseche:
- ucase(<stringa>):
restituisce la stringa con tutti i caratteri in
maiuscolo (i.e. ucase('anna')='ANNA');
- left(<stringa>,<n>):
restituisce i primi n caratteri di stringa (i.e. left('anna',2)='an');
- substring(<stringa>,<n>):
restituisce la stringa dal carattere n in
poi (i.e. substring('anna',2)='nna').