Laboratorio di Sistemi Informativi
Architettura a 3 livelli e server web
Architetture a due e tre livelli
Finora abbiamo visto come adoperare MySQL utilizzando dei client generici (come il monitor di MySQL) che consentono l'accesso a tutte le funzionalità del DBMS. In realtà, soltanto i programmatori e gli utenti avanzati hanno bisogno di accedere direttamente al DBMS, tutti gli altri utenti accedono ai dati tramite una opportuna interfaccia semplificata, che esenta l'utente dal conoscere SQL, la teoria dei database relazionali e la struttura logica della base di dati che utilizza.
Architettura cleint-server
Ci sono due approcci diversi allo sviluppo di applicazioni basate su DBMS.
Un approccio è quello client-server
puro. Abbiamo il server (MySQL) che esegue tutte le operazioni sulla
base di dati per conto di una applicazione client (la nostra
interfaccia
utente). I due componenti dialogano direttamente, tramite la rete, per
cui client e server possono anche risiedere su macchine diverse. Il
client traduce le richieste dell'utente in comandi SQL che invia al
server, il quale risponde aggiornando la base di dati ed eventualmente
restituendo il risultato delle query.
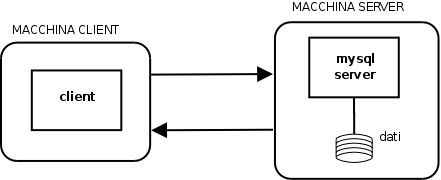
In una architettura client-server il client svolge in effetti due
funzioni diverse:
- interfaccia utente
- logica dell'applicazione
Ad esempio, l'interfaccia utente fornisce un menù a video con i
vari tipi di report possibili, e la parte di logica dell'applicazione
traduce la scelta "lista dei pagamenti giornalieri" nelle query
necessarie a recuperare dal database i dati necessari a produrre questo
report. Oppure, l'interfaccia utente può presentare un elenco di
oggetti che si possono acquistare, e la parte di logica si occupa di
modificare le tabelle in modo opportuno per registrare l'acquisto.
Architettura a 3 livelli
Con la diffusione di Internet e dei servizi ad essa
collegati, come il Web, si sta diffondendo un'architettura differente,
basata su tre livelli invece che due. Nell'architettura a tre livelli
(detta anche thin client) il
client non comunica direttamente con il server del database ma con un server dell'applicazione. In questo
modo il client svolge solo il compito di interfaccia utente e la logica
dell'applicazione viene inserita nel server applicativo. Questa
soluzione è sicuramente più modulare: se si modifica la
base di dati sottostante, il server dell'applicazione richiede a sua
volta delle modifiche, ma l'interfaccia utente può anche restare
invariata. Server applicativo e server di database possono risiedere
nella stessa macchina o su macchine diverse collegate in rete.
Nel caso particolare di Internet, il client è spesso un semplice
browser web come Firefox mentre il server
applicativo è un server web
come Apache. Un server web è un programma che fornisce pagine
HTML a un browser che le richiede. Queste pagine possono essere
statiche
(ovvero generate una volta per tutte) oppure dinamiche (generate ogni
volta ex-novo da un programma). È possibile quindi realizzare
una
pagina dinamica che generi automaticamente un report sui dati di un
database.
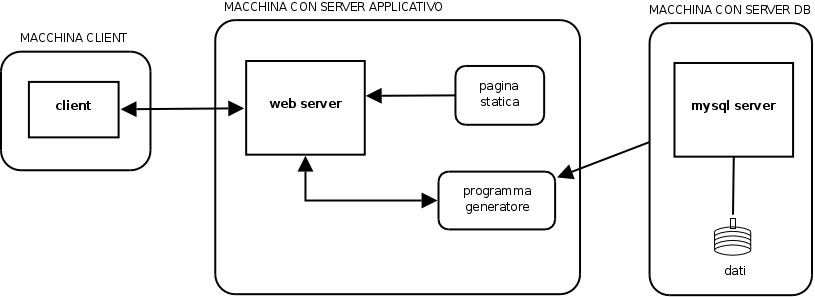
Noi utilizzeremo questo tipo di struttura a tre livelli. In particolare
adopereremo:
- il server web Apache. Si tratta probabilmente del server web più diffuso al mondo.
- il linguaggio di programmazione PHP.
Sviluppato appositamente per l'uso come generatore di pagine web,
è molto simile al linguaggio Java ed è ampiamente
utilizzato.
Un esempio di applicazione scritta in PHP è "Hugh and Dave's Online Wines" (un negozio di vini online), all'indirizzo http://www.webdatabasebook.com/2nd-edition/winestore/index.php, e descritta nel libro "Web Database Applications with PHP & MySQL". Non è una applicazione vera ma soltanto un esempio di ciò che si può fare, abbastanza facilmente, con PHP e MySQL.
Esempio di applicazioni reale (e decisamente complesse) scritte in PHP sono, tra mille altre,
SourceForge (adibita allo sviluppo e al supporto di vario software open source), e Facebook (che non ha bisogno di presentazioni).
Il server web Apache
Sia il server web Apache che il linguaggio PHP sono presenti nella distribuzione di Linux che stiamo utilizzando (la Ubuntu 8.04). Quando ci colleghiamo all'indirizzo http://<hostname>/percorso-pagina il browser si connette al computer <hostname> su Internet e chiede al suo server web di fornire la pagina (ovvero il file HTML) che corrisponde al percorso indicato. Se utilizziamo localhost come nome della macchina, il server web che viene contattato è proprio quello installato nella macchina locale.
Ma dove va a prendere le pagine web il nostro server? Tutto dipende da
come è configurato: normalmente, sulla Ubuntu, la directory
radice per le pagine web è /var/www
per cui l'accesso all'indirizzo http://localhost/provapagina/p2.html
indica al server web di leggere il file /var/www/provapagina/p2.html
e trasferirlo al browser. La directory radice per tutte le pagine web
viene chiamata document root.
Il problema è che soltanto root può accedere a queste directory (l'utente root del sistema
operativo, non quello di MySQL... ricordiamo che sono due cose
completamente distinte). Per consentire a tutti gli utenti di un server
di pubblicare facilmente le loro pagine web, alcuni indirizzi sono
interpretati in maniera speciale da Apache. In particolare una pagina
il cui indirizzo è http://<hostname>/~<username>/<percorso-pagina>
non viene cercata all'interno della document root, ma all'interno della
directory public_html nella home directory di <username>. Ad esempio l'indirizzo http://localhost/~pippo/prova.html corrisponde al file /home/pippo/public_html/prova.html.
Nota. Ricordiamo che per
scrivere il caratter
tilde (~) in Linux è possibile premere AltGr (il tasto a destra
dello spazio) e la i accentata. In alternativa, è
possibile sostituire la tilde con %7e.
Infatti in una URL, una stringa del tipo %xx viene rimpiazzata dal
carattere il cui codice ASCII (in esadecimale) è xx. Il
carattere tilde ha codice ASCII 126 che in esadecimale è proprio
7e.
ATTENZIONE: configurazione di Linux
Purtroppo, per motivi di sicurezza, su quasi tutte le distribuzioni Linux questa caratteristica di Apache va abilitata manualmente. Per maggiori informazioni, consultare il passo 2 della pagina "Guida alla configurazone di Ubuntu Linux".
In aula informatizzata, Apache è installato sul server goemon, dove risiedono anche le vostre home directory e il server MySQL. La document root non è accessibile, ma nella vostra home directory, se non l'avete cancellata, esiste già una directory di nome public_html. Tutti i file che mettete li dentro sono accessibili tramite il server web all'indirizzo http://goemon/~<username>/<nomefile>.
La prima pagina HTML
Vediamo un semplice esempio di pagina Web statica:
<!DOCTYPE HTML PUBLIC
"-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>Prova
HTML</title>
</head>
<body>
Ciao sono Gianluca
</body>
</html>
Possiamo memorizzarla col nome prova.html
all'interno della directory public_html
e accedervi dal browser all'indirizzo http://localhost/~<username>/prova.html.
Si tratta in questo caso di una pagina statica: tutte le volte che accediamo al suo indirizzo otteniamo sempre lo stesso risultato.
In aula informatizzata, per accedere al file dal browser usare l'indirizzo http://goemon/~<username>/prova.html.
Notare che è possibile vedere dal browser il codice HTML che
ha prodotto una determinata pagina. Basta cliccare col tasto destro sulla pagina web
è selezionare "View Page Source". Ovviamente, a parte il fatto
che le parole chiave sono colorate, il risultato è identico al contenuto del file
prova.html. Vedremo nella prossima lezione
che questo non è vero per quanto riguarda le pagine web dinamiche.
Cenni al protocollo HTTP (materiale aggiuntivo)
Vediamo adesso più in dettaglio come avviene la comunicazione tra il browser e il server. Quando sulla barra indirizzi del browser inseriamo un indirizzo basato sul protocollo HTTP, ad esempio http://sci138.sci.unich.it/~amato/teaching/labdati07, il browser fa quanto segue:
- si collega al server web del computer sci138.sci.unich.it (come questo avvenga è al di là del programma di questo corso);
- manda al server web un messaggio di richiesta per la pagina /~amato/teaching/labdati09;
- si mette in ascolto della pagina di risposta del server.
Questo è un tipico messaggio di richiesta per la pagina di cui sopra:
GET /~amato/teaching/labdati09/ HTTP/1.1
Host: sci138.sci.unich.it
User-Agent: Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.1.14) Gecko/20080418 Ubuntu/7.10 (gutsy) Firefox/2.0.0.14
Accept: text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
Accept-Language: en-us,en;q=0.7,it;q=0.3
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Keep-Alive: 300
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
Dopo il comando seguono una serie di linee, che costituiscono la intestazione della richiesta. Ogni linea ha sempre lo stesso formato <nome>: <valore>. Ogni linea ha un significato particolare: alcune sono obbligatorie, altre facoltative. Ad esempio, la riga
Accept-Encoding: gzip,deflate dice al server che, se vuole, la pagina di risposta può essere inviata in maniera compressa, usando i formati gzip oppure deflate.
Talvolta, dopo l'intestazione della richiesta segue anche un'ultima parte, il corpo della richiesta, ma su questo torneremo in futuro.
Una volta che la richiesta è terminata, il server web va a cercare la pagina, eventualmente esegue un opportuno programma generatore, e spedisce indietro il risultato. Ecco una possibile risposta per la richiesta di cui sopra:
HTTP/1.x 200 OK
Date: Thu, 24 Apr 2008 12:22:37 GMT
Server: Apache/2.2.4 (Ubuntu) DAV/2 SVN/1.4.4 PHP/5.2.3-1ubuntu6.3
Last-Modified: Mon, 07 Apr 2008 11:44:01 GMT
Etag: "6b8f97-22f8-fbe38240"
Accept-Ranges: bytes
Content-Length: 8952
Keep-Alive: timeout=15, max=97
Connection: Keep-Alive
Content-Type: text/html
........ testo della pagina .........
Anche la struttura della risposta è fissa. La prima riga indica se l'operazione ha avuto successo o si sono verificati degli errori. Nel nostro caso, la stringa HTTP/1.x 200 OK vuol dire che tutto è andato bene. Segue una intestazione della risposta, simile come struttura all'intestazione della richiesta, ma contenente tipicamente informazioni di altro tipo. Ad esempio la riga Content-Length: 8952 indica al browser che la pagina richiesta è lunga 8952 byte. L'intestazione è terminata da una riga bianca, seguita dalla pagina richiesta.
Notare che con lo stesso metodo vengono inviate anche le immagini, i file di stile, etc.... L'unica cosa che ambia è che, ad esempio, se la URL indicata dal browser punta a un file JPEG, nell'instetazione della risposta ci sarà la linea Content-Type: image/jpeg invece di Content-Type: text/html.
Torneremo in futuro sulla questione delle intestazioni del protocollo HTTP. Per adesso concludiamo notando che, se volete esaminare tutte le informazioni che server web e browser si scambiano, è disponibile un add-on per Firefox chiamato Live HTTP Headers. Provate a installarlo (non serve avere la password di root, perché si installa localmente nel vostro account) e fate alcuni esperimenti.
Esercizi
Esercizio 1
Salvate la pagina web presente qui sopra col nome prova.html dentro public_html (magari mettendo il vostro nome invece del mio). Provate ad accedere alla pagina web dal browser, con l'indirizzo http://<hostname>/~<username>/prova.html.
Esercizio 2
Installate l'add-on di Firefox "Live HTTP Headers" e adoperatelo per determinare quale server web è utilizzato dai seguenti siti: www.unich.it, www.repubblica.it e www.microsoft.com.

