Laboratorio di Sistemi Informativi
Architettura a 3 livelli e server web
Strutture a due e tre livelli
Finora abbiamo visto come adoperare MySQL utilizzando dei client
generici
(come il monitor di MySQL) che consentivano
l'accesso a tutte
le funzioni del DBMS. In realtà, soltanto gli sviluppatori dei
sistemi informativi hanno bisogno di accedere direttamente a MySQL,
mentre tutti gli altri utenti accederanno al database tramite una
opportuna interfaccia, realizzata dallo sviluppatore delle
applicazioni.
In questo modo l'utente non ha bisogno di conoscere SQL, la teoria dei
database relazionali e la struttura logica della base di dati che
utilizza.
Ci sono due approcci diversi allo sviluppo di applicazioni sui
database. Un approccio è quello client-server
puro. Abbiamo il server (MySQL) che esegue tutte le operazioni sulla
base di dati per conto di una applicazione client (la nostra
interfaccia
utente). I due componenti dialogano direttamente, tramite la rete, per
cui client e server possono anche risiedere su macchine diverse. Il
client traduce le richieste dell'utente in comandi SQL che invia al
server, il quale risponde aggiornando la base di dati ed eventualmente
restituendo il risultato delle query.
Struttura Client-Server
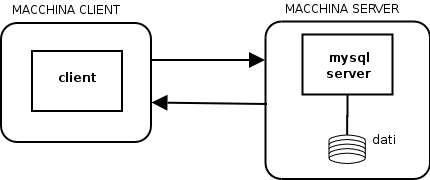
In una architettura client-server il client svolge in effetti due
funzioni diverse:
- interfaccia utente
- logica dell'applicazione
Ad esempio, l'interfaccia utente fornisce un menù a video con i
vari tipi di report possibili, e la parte di logica dell'applicazione
traduce la scelta "lista dei pagamenti giornalieri" nelle query
necessarie a recuperare dal database i dati necessari a produrre questo
report. Oppure, l'interfaccia utente può presentare un elenco di
voli che si possono prenotare, e la parte di logica si occupa di
modificare le tabelle in modo opportuno per effettuare la prenotazione.
Tuttavia, con la diffusione di Internet e dei servizi ad essa
collegati, come il Web, si sta diffondendo una architettura differente,
basata su tre livelli invece che due. Nella architettura a tre livelli
(detta anche thin client) il
client non comunica direttamente con il server del database ma con un server dell'applicazione. In questo
modo il client svolge solo il compito di interfaccia utente e la logica
dell'applicazione viene inserita nel server applicativo. Questa
soluzione è sicuramente più modulare: se si modifica la
base di dati sottostante, il server dell'applicazione richiede a sua
volta delle modifiche, ma l'interfaccia utente può anche restare
invariata. Server applicativo e server di database possono risiedere
nella stessa macchina o su macchine diverse collegate in rete.
Architettura a 3 livelli
Nel caso particolare di Internet, il client è spesso un semplice
browser web come Mozilla o Internet Explorer mentre il server
applicativo è un server web
come Apache. Un server web è un programma che fornisce pagine
HTML a un browser che le richiede. Queste pagine possono essere
statiche
(ovvero generate una volta per tutte) oppure dinamiche (generate ogni
volta ex-novo da un programma). E` possibile quindi realizzare
una
pagina dinamica che generi automaticamente un report sui dati di un
database.
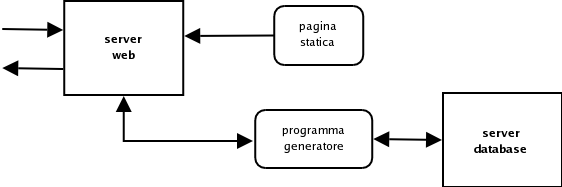
Noi utilizzeremo questo tipo di struttura a tre livelli. In particolare
adopereremo:
- il server web Apache, che
è probabilmente il più diffuso al mondo.
- PHP come linguaggio di
programmazione: è un linguaggio
sviluppato appositamente per l'uso come generatore di pagine web,
è molto simile al linguaggio Java ed è ampiamente
utilizzato.
Un esempio di applicazione scritta in PHP è "Hugh and Dave's Online Wines"
(un negozio di vini online), all'indirizzo http://www.webdatabasebook.com/2nd-edition/winestore/index.php,
e
descritto nel libro "Web Database
Applications with PHP & MySQL". Non è una
applicazione vera ma soltanto un esempio di utilizzo
di PHP
Un esempio di applicazione reale (e abbastanza complessa) scritta in
PHP è invece,
tra gli altri, il sito http://sourceforge.net/,
adibito allo sviluppo e al supporto di vario software open source.
Installazione server Apache e PHP
Sia il server web Apache che il PHP sono già installati nelle
macchine
del laboratorio e sono presenti nella distribuzione di Linux che stiamo
utilizzando (la Fedora Core 4). I pacchetti corrispondenti sono
httpd
(che sta per demone HTTP), php e php-mysql.
Provare ad esempio con rpm -qi
php per avere
informazioni sul pacchetto php installato.
Qualora fosse necessario, i file RPM per installare questi pacchetti si
posono scaricare da Internet o trovare nei CD della
distribuzione Fedora Core.
Tuttavia, la configurazione di default di Apache è stata scelta
per avere la maggio
re sicurezza possibile e non è adatta all'uso
che dobbiamo farne noi, perché alcune funzioni sono disattivate.
Inoltre, il server web non è impostato per partire
automaticamente all'avvio: ogni volta che si riavvia il sistema, occorre attivare Apache tramite l'applicazione: Desktop -> Impostazioni di Sistema -> Impostazioni del Server ->
Servizi, selezionando la voce httpd e premendo il pulsante avvia.
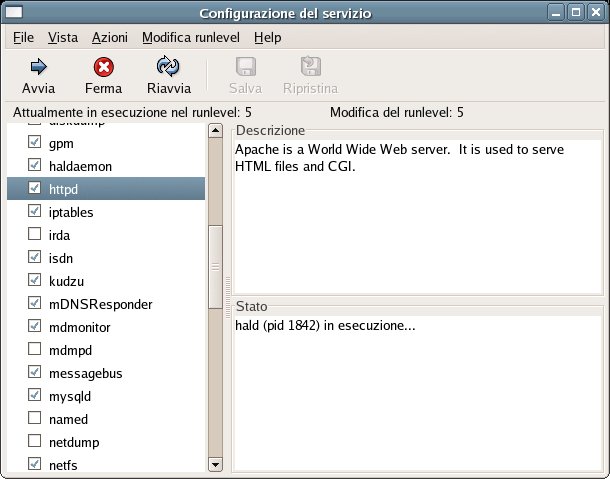
Volendo è possibile impostare il sistema in modo che Apache
parta automaticamente ad ogni avvio, attivando il segno di spunta accanto alla voce httpd e cliccando il pulsante Salva.
Tuttavia, la
cosa più convieniente è probabilmente installare il pacchetto RPM httpd-config-3-1.i386.rpm che,
automaticamente, configura il
sistema perché il server web parta automaticamente all'avvio e
modifica la configurazione di Apache per renderla più adatta
alle nostre esigenze.
Uso del server web
Quando ci colleghiamo all'indirizzo
http://x.y.z/percorso-pagina il browser si connette al computer
di
nome x.y.z in Internet e chiede al suo server web di fornire la pagina
(ovvero il file HTML) che corrisponde al percorso indicato. Al solito,
se utilizziamo
localhost come nome della macchina, il server web che viene
contattato è proprio quello installato nella macchina locale.
Ma dove va a prendere le pagine web il nostro server? Tutto dipende da
come è configurato: sulle macchine in laboratorio la directory
radice per le pagine web è /var/www/html
per cui l'accesso all'indirizzo http://localhost/provapagina/p2.html
indica al server web di leggere il file /var/www/html/provapagina/p2.html
e trasferirlo al browser. La directory radice per tutte le pagine web
viene chiamata document root.
Il problema è che soltanto root
può accedere a queste directory (l'utente root del sistema
operativo, non quello di MySQL... ricordiamo che sono due cose
completamente distinte). Per consentire a tutti gli utenti di un server
di pubblicare facilmente le loro pagine web, alcuni indirizzi sono
interpretati in maniera speciale da Apache. In particolare una pagina
il cui indirizzo è http://x.y.z/~pippo/percorso-pagina
non viene cercata all'interno della document root, ma all'interno della
directory public_html nella
home directory di pippo. In altre parole, l'indirizzo di sopra
corrisponde al file
/home/pippo/public_html/percorso_pagina. Analogamente http://x.y.z/~studente/index.html
corrisponde a /home/studente/public_html/index.html.
Noi metteremo le nostre pagine web proprio all'interno di /home/studente/public_html.
Nota! Ricordiamo che per
scrivere il caratter
tilde (~) in Linux è possibile premere AltGr (il tasto a destra
dello spazio) e la i accentata. In alternativa, è
possibile
rimpiazzare la tilde con %7e.
Infatti in una URL, una stringa del tipo %xx viene rimpiazzata dal
carattere il cui codice ASCII (in esadecimale) è xx. Il
carattere tilde ha codice ASCII 126 che in esadecimale è proprio
7e.
La prima pagina HTML
Vediamo un semplice esempio di pagina Web statica:
<!DOCTYPE HTML PUBLIC
"-//W3C//DTD HTML 4.0 Transitional//EN">
<html>
<head>
<title>Prova
HTML</title>
</head>
<body>
Ciao sono Gianluca
</body>
</html>
Possiamo memorizzarla col nome prova.html
su /home/studente/public_html
e accedervi dal browser all'indirizzo http://localhost/~studente/prova.html.
Si
tratta in questo caso di una pagina statica: ogni volta che si accede
al
suo indirizzo, il risultato che otteniamo è lo stesso.
NOTA! La directory public_html non viene creata
automaticamente al momento dell'installazione del sistema operativo, ma
va creata a mano dall'utente. Si può fare o dall'interfaccia
grafica o con il comando
mkdir /home/studente/public_html
In entrambi i casi, bisogna anche modificare i diritti di accesso alla
directory /home/studente.
Normalmente, tutte le home directory (almeno con la distribuzione
Fedora Core 4) sono protette: soltanto l'utente proprietario (studente nel nostro caso) ha il
diritto di entrare dentro, leggere il contenuto e creare nuovi file.
Siccome il server web viene eseguito come utente apache, non avrebbe il
diritto di entrare in /home/studente
(e quindi neanche in /home/studente/public_html).
Bisogna quindi concedere il permesso di esecuzione, a tutti gli
utenti, sulla directory /home/studente.
Si può fare o dalla interfaccia grafica, come abbiamo
visto nelle prime lezioni su Linux, o dalla shell con il comando:
chmod +x /home/studente
Questo non è un approccio molto sicuro, ma è
sicuramente il più semplice da adottare, e può essere
considerato adeguato per macchine monoutente.
Notare che è possibile vedere dal browser il codice HTML che
produce la pagina. Basta cliccare col tasto destro sulla pagina web
è selezionare "View Page Source". Ovviamente, a parte il fatto
che le parole chiave sono colorate, il risultato è identico a
quello del file prova.html. Vedremo tra un po' che questo non è
vero per quanto riguarda le pagine web dinamiche.
Esercizio
Salvate la pagina web presente qui sopra col nome prova.html in /home/studente/public_html
(magari mettendo il vostro nome invece del mio). Provate ad
accedere alla pagina web dal browser con l'indirizzo http://localhost/~studente/prova.html.
Provate poi a collegarvi al server web del vostro vicino sostituendo a
localhost l'indirizzo IP della sua macchina (vi ricordo il comando ifconfig per conoscere
l'indirizzo IP di una macchina).