Laboratorio di Sistemi Informativi
Introduzione a Linux
Come detto, questo non è un corso completo su Linux, per cui ci
limiteremo ad illustrare soltanto alcuni aspetti del sistema operativo.
Per una guida all'uso di Linux, si possono consultare:
- Appunti
di Informatica Libera, di Daniele Giacomini ed altri: un corso
omni-comprensivo,
dove trovate veramente di tutto. Si può anche scaricare qui
in vari formati.
- Introduzione
a Linux, di Marco Pratesi: un corso molto più breve, che
può essere letto dall'inizio alla fine.
Tutte le lezioni sono
pensate per la distribuzione Fedora Core 4, che è quella
installata nell'aula informatizzata. Cambiando distribuzione, alcuni
dettagli potrebbero essere differenti, in particolare per quanto
concerne
le interfacce grafiche. In generale, questo è il risultato di
uno dei grandi vantaggi (e svantaggi) di Linux, ovvero l'estrema
configurabilità: due macchine che eseguono Linux possono
apparire completamente diverse l'una dall'altra. Il vantaggio è
l'estrema adattabilità alle esigenze dell'utilizzatore, lo
svantaggio è che l'utente inesperto si trova disorientato
passando da un computer Linux a un altro.
Utilizzo generale dall'interfaccia grafica
L'utilizzo generale di Linux non è dissimile da quello di
Windows, soprattutto nelle ultime versioni. Ovviamente non ci si
può aspettare di trovare gli stessi programmi che si hanno su
Windows, ma quasi sempre ce n'è di equivalenti. Non ci
dilunghiamo quindi sul funzionamento generale ed andiamo ad analizzare
le differenze maggiori tra i due sistemi.
L'albero delle directory
Diamo una occhiata rapida all'albero delle directory di un sistema
Linux. A differenza di Windows, che è strutturato in modo da
avere (più o meno) una directory per ogni programma, in Linux la
struttura è molto più articolata. Lo strumento più
conveniente per analizzarne la struttura è il browser del
file-system, accessibile dal menù Applicazioni -> Strumenti di Sistema -> Esplorazione File.
/
+--- bin
+--- boot
+--- etc
+--- home
+--- luigino
+--- studente
+--- Desktop
+--- lib
+--- media
+--- cdrom
+--- floppy
+--- proc
+--- root
+--- sbin
+--- sys
+--- tmp
+--- usr
+--- bin
+--- lib
+--- var
Abbiamo qui indicato solo le directory più importanti.
Spieghiamole brevemente:
- / è la directory
principale, o directory radice. Notare
che, a differenza di Windows, il
simbolo per la radice è lo stesso simbolo usato per la divisione
e non la barra retroversa \
- /bin contiene i programmi
basilari per l'interazione con il sistema operativo. I vari comandi ls, ps, mkdir (che vedremo in seguito)
si trovano tutti in /bin
- /boot contiene il kernel
del sistema operativo, e serve soltanto durante la partenza del sistema
- /etc contiene i file di
configurazione globali del sistema (ogni utente poi ha dei file di
configurazione propri che stanno nella propria home directory). Di
solito ogni programma ha uno o più file di configurazione in
/etc che possono essere manipolati semplicemente come file di testo (a
differenza di Windows, dove spesso la configurazione dei programmi
è nascosta nel "registro di
configurazione", che può essere visualizzato e manipolato
solo col programma "regedit")
- /home contiene le home
directory dei vari utenti.
- /home/<nomeutente>è
la home directory dell'utente,
dove egli potrà memorizzare tutti i dati che vuole. In
particolare /home/studente è la directory dell'unico utente
disponibile in aula informatizzata. È questa directory che viene
aperta
quando, nel Desktop, si fa un doppio click sull'icona con la casa.
- /home/<nomeutente>/Desktop
corrisponde al Desktop dell'utente <nomeutente>. In
generale ogni utente si gestisce la proprio home directory come vuole,
ma la sottodirectory Desktop ha questo utilizzo particolare.
- /lib contiene le librerie
più importanti per il sistema. Una libreria è un insieme
di funzioni (nel senso di funzioni in C/C++) che possono essere usate
da tutti i programmi. Così, se una applicazione ha bisogno di
utilizzare delle funzioni di crittografia, può utilizzare la
libreria libcrypt.
Corrispondono alle DLL in Windows.
- /proc e /sys contengono dei file
speciali di interesse al sistema operativo. Ad esempio /proc/cpuinfo contiene informazioni
sulla/e cpu presente/i nel sistema.
- /root è la home
directory dell'utente root. L'utente root, presente in ogni sistema
Unix, è il super-utente. Ha dei diritti speciali, in quanto
può accedere a qualunque file e dispositivo presente nel
computer.
- /sbin contiene come /bin dei programmi fondamentali per
il sistema, ma tipicamente pensati per essere usati dal super-utente
(anche se spesso sono utilizzabili anche da un utente comune). Ad
esempio /sbin/lspci vi fa
vedere l'elenco delle periferiche PCI presenti nel sistema.
- /usr contiene molte
directory simili a quelle presente nella radice. Abbiamo così /usr/bin, /usr/sbin, /usr/lib. La differenza è che
i programmi e le librerie presenti in /usr non sono così
fondamentali come quelle presenti direttamente in /bin, /sbin o /lib. Ad esempio, GIMP si trova in /usr/bin.
- /tmp contiene dei file
temporanei usati da vari programmi
- /var contiene i dati dei
vari programmi presenti nel sistema. Vedremo ad esempio che MySQL mette
i propri database in /var.
Normalmente un utente (che non sia root) può leggere quasi tutti
i file presenti nel computer, ma può scrivere soltanto nella sua
home directory e nella directory /tmp.
La shell
Prima di iniziare veramente a parlare di MySQL è bene
familiarizzare con un ambiente software che probabilmente non
conoscete: la "shell".
Nei sistemi Unix, la shell è il programma più importante,
dopo il kernel.
È il mezzo con cui si comunica con il sistema e
attraverso
il quale si avvia e si controlla l'esecuzione degli altri programmi.
Shell vuol dire "conchiglia" e il nome deriva dal fatto che è la
superficie con cui l'utente entra in contatto quando vuole interagire
con il sistema: la shell che racchiude il kernel.
Una volta, prima dell'avvento delle interfacce grafiche, la shell era
l'unico sistema per comunicare con il sistema operativo. Oggi non
è più così, ma la shell, per chi la sa usare,
conserva ancora dei vantaggi rispetto all'interfaccia grafica:
- per la maggior parte dei compiti, è più veloce dare
un comando con la shell che aprire finestre e finestrelle, anche
perchè non bisogna mai spostare le mani dalla tastiera per
raggiungere il mouse;
- è programmabile: la shell è un vero e proprio
linguaggio di programmazione con il quale è possibile
automatizzare l'esecuzione di vari compiti;
- alcune attività di basso livello richiedono l'uso della
shell, persino in ambiente Windows;
- è utilizzabile da un computer remoto, e in questo modo si
ha l'accesso totale alla macchina, che può essere amministrata
senza bisogno di essere presenti fisicamente nello stesso luogo.
La shell è disponibile anche per sistemi Windows, anche se
lì si chiama, per motivi storici "prompt dell'MS-DOS" o "prompt dei comandi". Tuttavia,
essa è molto meno potente che nei sistemi Unix, per cui è
di solito meno utilizzata.
In realtà in Unix esistono varie shell dei comandi, ma le due
più utilizzate sono sicuramente la bash e la tcsh, che hanno
ovuto origine nei sistemi Unix System V e BSD rispettivamente. Noi
studieremo la bash perchè è quella standard di Linux.
Il prompt dei comandi
Per attivare la shell, il modo più comodo è,
dall'ambiente grafico, attivare il programma Terminale (dal
menù Applicazioni
-> Strumenti di Sistema ->
Terminale). Si
presenta una finestra simile a questa:

La scritta "amato@sci138:~$"
è il prompt dei comandi: indica che la shell è attiva e
pronta ad accettare richieste dall'utente. Riconosciamo le seguenti
componenti nel prompt:
- amato: il nome
dell'utente che sta utilizzando la shell. Nel caso dell'aula
informatizzata, l'unico utente esistente è "studente".
- sci138: il nome del
computer. Nel caso dell'aula informatizzata, i computer non hanno un
nome specifico, e si chiamano tutti "localhost".
- ~: la directory
corrente. Il simbolo ~ indica la "home directory" dell'utente in
corso (in questo caso l'utente amato) ed è una abbreviazione per
il percorso /home/<nomeutente>.
- $: indica che
l'utente amato è un utente normale.. se fosse un super-utente,
dotato di privilegi particolari per l'amministrazione di sistema, il $
sarebbe sostituito da #.
Attenzione: è
possibile modificare il prompt rispetto a quello
di default... per cui non fate troppo affidamento a questa descrizione.
Dal prompt è possibile digitare i comandi che si vogliano
inviare
al sistema, utilizzando anche i tasti standard per l'editing: Canc,
Backspace, Inizio, Fine, Freccia sx, Freccia dx. I tasti Freccia su e
giù consentono invece di scorrere i comandi già immessi
precedentemente, che possono poi essere modificati.
Alcuni comandi
Dalla shell è possibile inviare dei comandi al sistema
operativo.
Ecco alcuni esempi:
- ls: visualizza il
contenuto della directory corrente. Colori diversi indicano tipi di
file diversi. Ad esempio le directory sono in blu.
- cat <nomefile>:
visualizza il contenuto del file <nomefile>
- less <nomefile>:
visualizza il contenuto del file <nomefile>, una pagina alla volta
- cd <nuovadirectory>:
cambia directory corrente
- pwd : visualizza il percorso della
directory corrente
- mkdir <nuovadirectory>:
crea una nuova directory
- rmdir <directory>:
cancella la directory specificata (se è vuota)
- cp <fileorigine>
<filedestinazione>: copia un file dall'origine alla
destinazione
- mv <fileorigine>
<filedestinazione>: sposta un file dall'origine alla
destinazione (come cp ma cancella l'originale)
- rm <file>:
cancella il file specificato
- touch <file>:
crea un file vuoto se non esiste già, altrimenti aggiorna la
data di ultima modifica del file.
La struttura generale di un comando è
<nomeprogramma>
<lista di argomenti>
Tipicamente un comando della shell non è altro che il
nome di un programma che il sistema operativo deve eseguire: ls, cat, cp, mv sono tutti programmi. Ma
anche programmi più "corposi" possono essere eseguiti
semplicemente dando il nome dalla shell. Non vi ricordate più in
che menù sta nascosto il programma di grafica GIMP ? Basta dare
il comando gimp e questo
partirà regolarmente.
Percorsi assoluti e relativi
Abbiamo visto che molti comandi hanno come argomento un nome di file.
Ma che struttura ha un nome di file Linux? Nel vecchio sistema
operativo DOS, il nome aveva una struttura fissa di 8 caratteri, un
punto, e altri 3 caratteri (detti estensione).
L'estensione serviva a identificare il tipo di file: .jpg per file immagini JPEG, .txt per file di testo puri, .doc per file Word, etc..
Su Linux (e Windows), un nome di file è una stringa di caratteri
qualunque, e può contenere quanti punti si desidera (anche
nessuno). L'estensione non è necessaria, ma spesso la si
aggiunge per facilitare la vita all'utilizzatore del computer, che
così è in grado di riconoscere il tipo di ogni file.
Anche alcuni programmi si basano sull'estensione di un file per
decidere come trattarlo. Notare che, su questi sistemi, l'estensione
può anche essere più lunga di 3 caratteri: ad esempio .html è l'estensione
standard per i file HTML.
Tuttavia, specificare semplicemente il nome di un file non è
sufficiente. Infatti, all'interno del file system possono esserci molti
file con lo stesso norme, purchè stiano in directory diverse.
Come si fa, allora, a indicare con esattezza un file specifico, in modo
che non sorgano ambiguità? Bisogna utilizzare i pathname (nomi dei percorsi) che
possono essere di due tipi: assoluti o relativi.
Un percorso assoluto è
una stringa del tipo:
/<nomedir>/<nomedir>/<nomedir>/<nomefile>
che inizia con la barra di divisione, ha una serie di componenti
separati da barre e termina con un nome di file. La sequenza dei vari
<nomedir> è la sequenza di directory dentro le quali il
sistema deve entrare, partendo
dalla radice, per raggiungere la directory dove si trova il
<nomefile> desiderato. Ad esempio:
- /home/studente/prova.txt
si riferisce a un file prova.txt
nella home directory di studente.
- /abcd si riferisce a
un file di nome abcd
(senza estensione) dentro la directory radice.
Sono importanti alcune cose:
- il percorso assoluto deve
iniziare con la barra di divisione;
- la barra da utilizzare è quella per la divisione (/)
e non la barra retroversa (\) che si usa invece nei sistemi Windows;
- è necessario specificare la sequenza completa di tutte le
directory da attraversare per arrivare al file desiderato.
Ogni processo (programma in esecuzione) in Linux ha una directory corrente. Quando si
specifica un nome di file direttamente, senza percorso, il file viene
cercato in questa directory. Per cambiare directory corrente nella shell di Linux, si può
usare il comando cd
(change dir). Più in generale, la directory corrente serve come
punto di riferimento per i percorsi relativi.
Un percorso relativo è
una stringa di questo tipo:
<nomedir>/<nomedir>/<nomedir>/<nomefile>
quindi è simile a un percorso assoluto ma non ha la barra iniziale.
Anche il significato è simile a quello di un percorso assoluto,
con la differenza che la directory da cui iniziare la ricerca del file
non è la directory radice ma la directory corrente. Nei percorsi
relativi si una spesso una directory speciale, la directory .. (due punti), che indica la
directory padre di quella corrente, consentendo quindi di risalire
l'albero delle directory. Ad esempio, se la directory corrente è
/home, allora:
- studente/prova.txt
si riferisce a un file prova.txt
nella home directory di studente.
- ../abcd si riferisce
a un file di nome abcd
(senza estensione) dentro la directory radice.
Di solito ovunque si può inserire il nome di un file, si
può inserire un percorso assoluto o relativo. Ma quale conviene
usare tra i due? Quando si usa la shell in maniera interattiva, come
facciamo noi in questa lezione, si può usare quello che ci torna
più comodo. Quando però si scrivono dei programmi che
hanno bisogno di accedere a vari file ad essi correlati, è
meglio utilizzare percorsi relativi. In questo modo, sarà poi
più facile spostare tutto il software da una directory ad un
altra senza comprometterne il funzionamento.
Ad esempio, supponiamo di aver scritto un programma vis che ha bisogno di alcune
immagini per funzionare. Decidiamo di mettere il programma vis nella directory /home/studente/prg e le
immagini in una sottodirectory, ad esempio /home/studente/prg/img. Quando
nel programma abbiamo bisogno di riferirci ad una immagine, è
meglio se usiamo un percorso relativo alla directory /home/studente/prg.
Così, l'immagine titolo.jpg
dovrà essere riferita con il percorso img/titolo.jpg. In questo modo,
quando ci porteremo il programma a casa nel nostro computer, potremo
decidere di mettere il tutto (il programma vis e la sottodirectory img) nella directory /usr/local/mioprog e il
programma continuerà a funzionare a dovere. La vecchia immagine /home/studente/prg/img/titolo.jpg
non esiste più, ma al suo posto abbiamo /usr/local/mioprog/titolo.jpg
e, partendo da /usr/local/mioprog
il percorso relativo img/titolo.jpg
punta propro a quest'ultima.
Esercizio 1
All'interno della home directory di studente, creare una cartella prova e, dentro quest'ultima,
una ulteriore cartella prova-nidificata.
Creare dentro prova-nidificata
un file di testo di nome provatesto.txt
con un contenuto a piacere (come editor di testi si può usare gedit). Controllare che
il contenuto sia leggibile usando il comando cat. A questo punto copiare il
file provatesto.txt nella
directory prova con il
nuovo nome provatesto2.txt,
e cancellare la directory prova-nidificata.
Comandi e opzioni
A molti dei comandi visti finora è possibile aggiungere delle
opzioni per alterarne il funzionamento. Ad esempio, ls può prendere come
argomento i seguenti parametri (e tanti altri che qui non cito):
- -a : visualizza
tutti i file, anche quelli nascosti.
In Linux un file nascosto è
un file che inizia con il punto. ('a' sta per all)
- -l : visualizza, per
ogni file, un dettaglio dei suoi attributi
(lunghezza in byte,
data di ultima modifica, utente e gruppo, diritti di accesso).
('l' sta per 'long')
Quelle che abbiamo visto qua sopra sono le "opzioni corte". Esse hanno
tutte la stessa forma: il segno - seguito lettera. Alcuni programmi
supportano anche delle opzioni lunghe. Ad esempio in ls abbiamo
- --all: equivalente a
-a
- --help: visualizza
una spiegazione succinta del funzionamento di ls e di tutte le opzioni
previste.
- --version:
visualizza la versione del programma ls.
Le opzioni possono essere combinate tra di loro. Ad esempio 'ls -a -l' visualizza tutti i
file, compresi quelli nascosti, e visualizza per ognuno i suoi
attributi. Stesso risultato da 'ls
--all -l'. Un altro modo di combiare le opzioni corte è
usare un unico simbolo -
e, in
sequenza, le lettere corrispondenti alle varie opzioni. Ad esempio 'ls -al' ha lo stesso effetto di
'ls -a -l'.
NOTA. Le opzioni --help e --version sono comuni a molti
programmi. Se non si sa cosa fa il programma chown, il comando chown --help è un buon
modo per scoprirlo.
Completamento automatico
Una caratteristica utile della shell di Linux è il completamente
automatico. In varie circostante potete premere il tasto <TAB> e
la shell completa quello che state scrivendo nella maniera più
ovvia. Se ad esempio siete nella situazione
amato@sci138$ pass
e premete <TAB>, la stringa pass
viene completata in passwd
(il comando per cambiare la propria password). Questo perchè passwd è l'unico comando
che inizia con pass.
Analogamente, se nella directory corrente c'è il file "prova" e
voi premete <TAB> quando avete digitato
amato@sci138$ cat pr
allora pr viene
completato in prova.
In generale, quasi su ogni sistema è vero quanto segue:
- se premete <TAB> sulla prima parola di una riga di comando,
la shell tenta di completare la stringa immessa con un comando valido;
- se premete <TAB> sulle parole successive alla prima in una
riga di comando, la
shell tenta di completare la stringa con un nome di file valido.
Talvolta premendo <TAB> non succede niente: vuol dire che
c'è ambiguità nel modo in cui si può completare la
stringa. Ad esempio, se abbiamo anche il file prato oltre a prova, premere <TAB> dopo
pr è ambiguo perchè pr
potrebbe essere completato con prato o con prova.
In questo caso, si può premmere <TAB> due volte di seguito
per avere l'elenco dei possibili completamenti. Ad esempio, con
amato@sci138$ rm
premendo <TAB><TAB> si ha l'elenco dei comandi che iniziano
con rm:
rm
rmail.sendmail
rmic
rmiregistry
rmail
rmdir rmid
Il <TAB> può essere usato per spostarsi velocemente
nell'albero delle directory. Se si vuole visualizzare il file /var/spool/mail/studente (che
contiene la posta in arrivo per l'utente studente) il comando da dare
è cat
/var/spool/mail/studente. Si può scrivere questo comando
molto più velocemente digitando: cat
/v<TAB>/sp<TAB>/ma<TAB>/s<TAB>. Se
invece volete visualizzare un file in /var/spool/mail ma non vi
ricordate quale, potete provare con cat
/var/spool/mail/<TAB><TAB> che visualizza l'elenco
dei file in /var/spool/mail.
La funzione di completamento automatico è veramente comoda. Una
volta che ci si è famirializzato, è difficile
farne a meno.
Immissione caratteri speciali
Spesso è necessario inserire dei caratteri che non sono presenti
nella tastiera. Come si fa in questo caso? Il trucco tipico di Windows
(ALT+il codice ascii sul tastierino numerico) su Linux non funziona. In
realtà, i caratteri più comuni possono essere digitati
con alcune combinazioni di tasti standard:
- Alt-Gr + apostrofo = apice
- Alt-Gr + ì = ~
- Alt-Gr + e = €
- Alt-Gr + é = Alt-Gr + Shift + è = {
- Alt-Gr + * = Alt-Gr + Shift + più = }
Altri caratteri possono essere digitati utilizzando la funzione
Multi_key. Premendo Shift + AltGr (nell'ordine prima shift, poi
Alt-Gr) viene attivata la funzione Multi_key: a quel punto Linux si
aspetta due caratteri in sequenza, che vegono combinati per formare un
unico carattere. Ad esempio
- Multi_key s s = ß
- Multi_key ` E = È
- Multi_key A E = Æ
e così via..
Aiuto, non mi ricordo cosa
fa un comando
Nessuno è ingrado di ricordarsi tutti i possibili comandi e le
differenti opzioni disponibili in ambiente Unix. Per questo la
documentazione in materia è estensiva. Abbiamo già visto
l'opzione --help che
è possibile fornire a molti comandi per farci restituire la
spiegazione del suo funzionamento e delle opzioni che supporta. La
spiegazione che si ottiene è però spesso troppo
stringata, utile quando il comando lo si conosce già e
semplicemente non ci si ricorda il formato di qualche opzione, ma non
quando si vuole imparare come utilizzarlo.
Per quest'ultimo scopo è molto più utile il comando man. Si usa generalmente in
questo modo:
- man <comando>:
visualizza il manuale utente per il comando.
Ad esempio man rmdir
visualizza il manuale del comando rmdir.
La lettura del manuale non è sempre agevole e bisogna abituarsi
un po', anche perchè spesso le spiegazioni sono molto tecniche.
Le due parti più importanti sono tipicamente SYNOPSIS che dà la sintassi
del comando e DESCRIPTION che
spiega cosa fa il comando e il significato di tutte le opzioni
disponibili.
NOTA. Un'altra fonte di
informazione sono i file presenti in
/usr/share/doc/<nomepacchetto>.
E poi ovviamente Internet, che è la più grossa fonte di
informazione in materia.
Esercizio 2
Creare la directory prova-nidificato2
dentro la directory prova
e prova-nidificato3
dentro prova-nidificato.
Creare un file di testo prova-file
dentro prova-nidificato3
con un contenuto a piacere. Il metodo standard che abbiamo visto
per cancellare una directory dalla shell è quello di cancellare
prima i file che essa contiene con rm e poi la caretlla stessa con
rmdir. Senza seguire
questa
procedura, consultare la documentazione sul comando rm e capire come cancellare,
con un unico comando, la directory prova e tutte le sue
sottodirectory.
Accesso ai dischi e operazioni di montaggio
Nei sistemi Unix non esiste il concetto di "lettera
del dispositivo" per accedere ai floppy, CD-ROM o semplicemente a
partizioni differenti dell'hard-disk. I file contenuti in questi
dispositivi vengono semplicemente inseriti all'interno dell'albero
principale delle directory. In particolare, /media/cdrom e /media/floppy
corrispondono al contenuto del CDRom e del floppy rispettivamente.
Normalmente, se si tenta di visualizzare una di queste directory, essa
appare vuota. Perchè si verifichi il collegamento tra
/media/floppy (e simili) e il corrispondente dispositivo, occurre
effetturare una operazione speciale detta "montaggio".
Dall'interfaccia grafica, è possibile "montare" i floppy o i cdrom aprendo la cartella
"Computer" presente sul Desktop e da lì con un doppio click su
"Floppy Drive" o "CD-R Drive". In realtà, spesso, il montaggio
dei CD-ROM è automatico, basta inserire il disco nel lettore. A
seguito
di questa operazione accadono due cose (supponendo che tutto vada bene):
- una icona appare nel Desktop dalla quale è possibile
accedere ai file del dispositivo;
- il filesystem presente nel dispositivo viene montato nell'albero
principale delle directory.
Dopo il montaggio di un floppy, ad esempio, si può andare in /media/floppy e operare
normalmente dentro quella directory, senza preoccuparsi del fatto che i
file risiedono sul floppy piuttsto che sull'hard disk.
Analoga alla operazione di montaggio c'è l'operazione di
"smontaggio". Dall'interfaccia grafica basta cliccare sull'icona del
dispositivo e seleziona "Espelli". Questo causa lo smontaggio del
dispotivo (che non è più visibile all'interno della
directory /media/.....)
e,
nel caso del CDRom, l'espulsione del CD.
Attenzione, l'operazione di smontaggio è importantissima,
in particolare per
i floppy. Quando scriviamo su un floppy, infatti, non è detto
che il sistema operativo faccia subito le scritture. Può darsi
che si tenga i dati nella cache. Quando si esegue lo smontaggio, tutte
le operazioni pendenti di scrittura vengono portate a termine. Se si
estrae il floppy prima di smontarlo, c'è il rischio di trovarsi
con modifiche non effettuate o peggio con il file-system corrotto. Per
i CD la questione è meno delicata perchè tanto sono
dispositivi di sola lettura. Tuttavia, è probabile che,
finchè il CD è montato, il tasto di espulsione manuale
non funzioni.
File, utenti, diritti
Unix è un sistema operativo multi-utente. Vuol dire che
più persone possono utilizzare il computer, anche
contemporaneamente, e il sistema deve garantire un certo livello di
sicurezza: impedire, ad esempio, che i file privati di un utente
possano essere letti da un altro senza autorizzazione.
Noi descriveremsistema di gestione dei diritti standard di Linux.
Ultimamente ci sono stati vari sviluppi per aumentare ulteriormente la
sicurezza e la protezione del sistema: tra questi SELinux (Security
Ehanco il ed Linux) che è di default nella Fedora Core 4, ma che non
è abilitato in aula informatizzata.
Utenti e gruppi
Due sono i concetti principali per tutte le politiche di sicurezza:
l'utente e il gruppo. Quando si effettua il login, bisogna
specificare la username con cui ci si collega e la password relativa.
Un elenco di tutti gli utenti del sistema si può trovare, di
solito, nel file /etc/passwd
(che non commenteremo oltre), mentre un elenco dei gruppi si trova in /etc/group. Per sapere
l'utente e il gruppo corrente, basta dare il comando
- id : restituisce
utente e gruppo corrente, in una forma del tipo:
uid=500(studente)
gid=500(studente) gruppi=500(studente)
context=user_u:system_r:unconfined_t
La riga di sopra ci dice che siamo correntemente collegati con la
seguente identità:
- uid=500(studente):
l'identificatore utente (user id) attuale è 500 e nome simbolico
corrispondente è studente.
- gruppi=500(studente)
: si fa parte del gruppo 500, il cui nome simbolico è studente.
Anche se in quqesto caso identificatori utente e gruppo coincidono
questo non è assicurato. Inoltre, un utente può far parte
di più gruppi.
File e diritti
È possibile specificare i diritti di accesso degli utenti ai
file in base ai due concetti di utente e di gruppo. Ogni file presente
sul sistema appartiene ad un utente e a un gruppo ben specifico: si
chiamano i proprietari del
file.
Le operazioni che è possibile compiere su un file si possono
dividere in 3 grossi gruppi:
- lettura
- scrittura
- esecuzione
Ognuna di queste operazioni può essere concessa o negata a tre
diversi tipi di utente:
- al proprietario del file
- ad un utente che appartiene al gruppo proprietario del file
- ad un utente diverso da quelli di sopra.
È così possibile specificare che il file pippo.sh può essere
letto e scritto dal suo proprietario, solo letto da un altro utente del
gruppo, e completamente inaccessibile a un'altra persona.
Ma come si fa a sapere chi è il proprietario di un file e quali
sono i permessi di accesso? Dalla interfaccia grafica basta cliccare
col tasto destro sul file che ci interessa e selezionare Proprietà dal
menù contestuale che viene fuori. Selezionando la cartellina Permessi si otterrano tutte le
informazioni volute e sarà anche possibile modificarle.
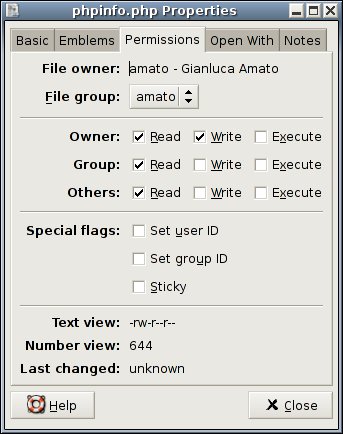
Diritti di esecuzione per le directory
I diritti di lettura, scrittura ed esecuzione si possono concedere
anche a delle directory. Ma mentre sembra chiaro cosa vuol dire lettura
e scrittura per una directory, cosa vuol dire "esecuzione" in questo
caso?
Avere il diritto di esecuzione su una directory vuol dire essere in
grado di entrare in una directory. È possibile anche
accedere ai file che stanno in quella directory, purchè se ne conosca il nome!!
Tuttavia il diritto di esecuzione non ci consente di esaminare il
contenuto di una directory con ls.
Quest'ultima operazione è possibile solo se sulla directory
abbiamo il diritto di lettura.
Processi
Un sistema Unix, in ogni momento, ha un certo numero di processi in
esecuzione. Un processo viene creato quando si esegue un comando o un
programma più complesso. Si possono esaminare i processi
attualmamente in corso, al solito, o con una interfaccia grafica o con
la shell.
Dall'interfaccia grafica, il programma da utilizzare è Applicazioni -> Strumenti di Sistema
-> Monitor di Sistema.
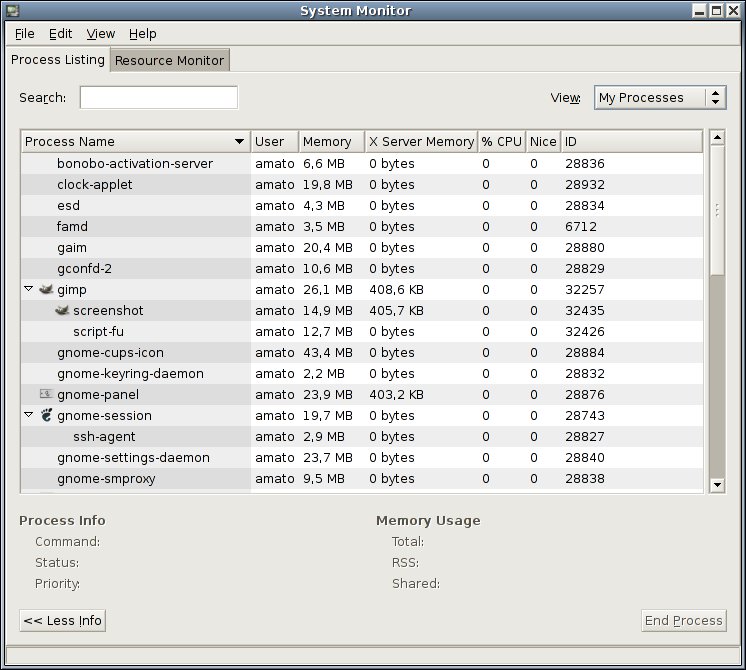
Si vede un elenco di processi e, per ognuno di essi, alcune sue
caratteristiche. Le cose più importanti sono le prime due
colonne, il nome del processo e l'utente che lo controlla. Ogni
processo ha gli stessi diritti di accesso ai file dell'utente che lo
controlla. Normalmente il Monitor fa vedere solo i processi sotto
controllo dell'utente che lo ha invocato, ma è possibile
selezionare "Tutti i Processi" in alto a destra e ottenere la
visualizzazione completa.
E` anche possibile "uccidere" un processo che non risponde più
ai comandi utente, cliccando col tasto destro sul processo e scegliendo
Termina Processo dal
menù contestuale che appare. Qualora neanche questo modo
consente di interrompere il processo, si può scegliere Uccidi Processo invece di Termina Processo dallo stesso
menù. E` però una cosa da fare come ultima risorsa
perchè è un metodo molto brutale che non da il tempo al
processo ucciso di salvare i dati eventualmente modificati.
Installazione di programmi in Linux
Spiegamo brevemente come si fa ad installare del software sotto Linux.
Nel caso della Fedora 4, se il software fa parte della distribuzione
standard possiamo installarlo scegliendo Sistema -> Impostazioni di Sistema
-> Aggiungi/Rimuovi Applicazioni. Tuttavia, nel caso
in cui il software non fa parte della distribuzione standard, occorrera
procurarselo in qualche, tipicamente scaricandolo da Internet, e
installarlo.
Esistono vari modi e formati in cui il software può essere
distribuito, ma noi ci occuperemo solo del caso di programmi
distribuiti in formato RPM
(RedHat Package Manager). Un file in formato RPM
è un file compresso (simile a un file ZIP) che contiene delle
informazioni speciali per
l'installazione e disinstallazione di software. Per manipolare i file
RPM conviene imparare l'utilizzo dell'omonimo comando rpm (che è un programma
Linux privo di interfaccia grafica, quindi va eseguito dalla shell).
Il comando fondamentale da imparare è
- rpm -U <lista nomi file
rpm> : installa i pacchetti RPM dati come argomenti. Se
esiste già un versione precedente del pacchetto, lo aggiorna con
la nuova versione.
Ad esempio, con rpm -U
MySQL-server-4.0.18-0.i386.rpm viene installato il pacchetto RPM
che contiene il server MySQL, nella versione 4.0.18-0. Talvolta un
pacchetto non può
essere installato perchè il suo funzionamento dipende da un
altro pacchetto presente nel sistema. Ad esempio
rpm -U MySQL-Max-4.0.18-0.i386.rpm
fallisce se non è stato prima installato MySQL-server. In questo
caso, o si eseguono i due comandi in sequenza:
rpm -U
MySQL-server-4.0.18-0.i386.rpm
rpm -U MySQL-Max-4.0.18-0.i386.rpm
oppure si indicano in un unico comando tutti gli RPM necessari:
rpm -U
MySQL-server-4.0.18-0.i386.rpm MySQL-Max-4.0.18-0.i386.rpm
E` possibile sapere che pacchetti sono installati, sempre con il
comando rpm, in questo
modo:
- rpm -q <nompacchetto>
: restituisce la versione del pacchetto installata. Ad esempio rpm -q MySQL-server restituisce
MySQL-server-4.0.18-0. Notare che in
<nomepacchetto> va il nome del pacchetto e NON il nome del file
usato per l'installazione. In altre parole, il comando da dare
è rpm -q MySQL-server
e non rpm -q
MySQL-server-4.0.18-0.i386.rpm.
- rpm -qi
<nomepacchetto> : restituisce una descrizione del
pacchetto indicato come argomento.
- rpm -ql
<nomepacchetto> : restituisce un elenco di file che fanno
parte del pacchetto
- rpm -qa :
restituisce l'elenco dei pacchetti installati. Visto che l'elenco
è molto lungo, conviene salvarlo su un file, per consultarlo poi
con calma.
La sintassi in questo caso è rpm -qa > <nomefile>.
Nota. L'uso di "> <nomefile>" non
è una
caratteristica del comando RPM ma una possibilità che il sistema
operativo ci mette a disposizione per tutti i comandi che hanno un
output testuale. Il simbolo di maggiore indica al sistema operativo di
mandare l'output del programma sul file specificato piuttosto che sullo
schermo. Quindi ls > lista.txt
manderà l'ouput del comando ls nel file lista.txt.
L'opzione -q di rpm si
può usare anche per avere informazione su
un file RPM prima di installarlo. In questo caso la sintassi è:
- rpm -qip <nome file
RPM> : visualizza una descrizione del pacchetto presente nel
file
- rpm -qlp <nome file
RPM> : visualizza l'elenco dei file che verrebbero creati
dall'installazione del pacchetto.